雅虎EGADS项目源码解析
EGADS是什么?
EGADS(Extendible Generic Anomaly Detection System)是雅虎开源的一个大规模时间序列异常检测项目。它的目标是提供一个通用的、可扩展的、易于使用的框架,用于检测各种类型的时间序列数据中的异常点。
时间序列数据是指按照时间顺序排列的一组数据点,它们通常反映了某个变量随着时间的变化趋势。例如,某个城市每天的气温、某个网站每小时的访问量、某个股票每分钟的价格等,都是时间序列数据的例子。
异常检测是指在时间序列数据中寻找那些与正常情况下有很大偏差的数据点,它们通常反映了某种异常或突变的情况。例如,某个城市某天的气温突然升高或降低、某个网站某小时的访问量突然增加或减少、某个股票某分钟的价格突然上涨或下跌等,都是异常检测的例子。
EGADS如何工作?
Egads(Extensible Generic Anomaly Detection System)是一个用于自动检测大规模时间序列数据中的异常的开源Java包。它主要由两个模块构成,一个是时间序列建模模块(TMM),另一个是异常检测模块(ADM)。
时间序列建模模块(TMM): 是用于预测时间序列数据中每个点的正常值的,它可以使用不同的算法来建立不同类型的时间序列模型,例如周期性最近邻(PNN)、奥林匹克模型(OlympicModel)、指数平滑(ExponentialSmoothing)等。
异常检测模块(ADM): 是用于比较时间序列数据中每个点的实际值和预期值,并根据一定的阈值来判断是否为异常点的,它也可以使用不同的算法来实现不同类型的异常检测模型,例如极低密度模型(ExtremeLowDensityModel)、K西格玛模型(KSigmaModel)、自适应核密度变点检测器(AdaptiveKernelDensityChangePointDetector)等。
源码阅读
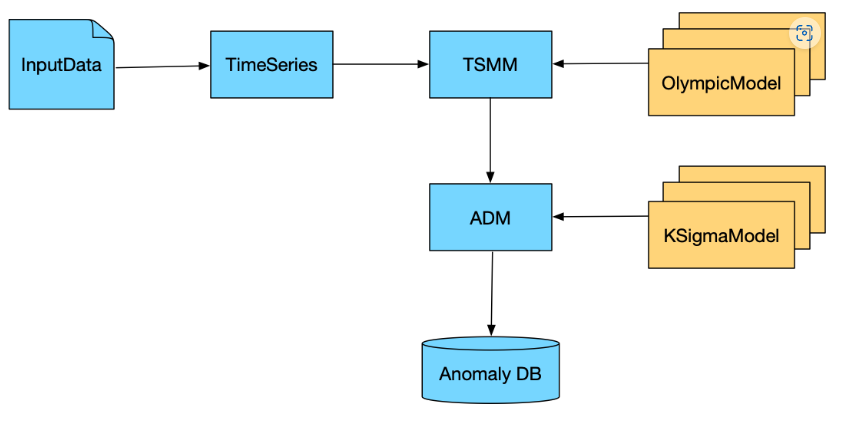
我们时间序列以OlympicModel,异常检测KSigmaModel为例.
在阅读源码前,我们先理解几个概念:
1.EGADS的预测是针对过去时间数据的预测,而不是对未来时间数据的预测.
2.时间序列数据示例如下,实际数据可能是按秒或者分钟为单位时间间隔的数据
| 日期 | 气温 |
|---|---|
| 1月1日 | 10℃ |
| 1月2日 | 12℃ |
| 1月3日 | 11℃ |
| 1月4日 | 9℃ |
| 1月5日 | 13℃ |
| 1月6日 | 8℃ |
| 1月7日 | 15℃ |
| 1月8日 | 10℃ |
| 1月9日 | 12℃ |
| 1月10日 | 11℃ |
| 1月11日 | 9℃ |
| 1月12日 | 13℃ |
| 1月13日 | 8℃ |
| 1月14日 | 15℃ |
3.项目中的config.ini配置文件中的配置至关重要.不要忽略!预测数据与期望数据的长度尽量保持一致,具体原因可以查看predict方法的实现.
开始工作
我们直接从Egads这个类入手,可以发现这个方法中,主要是通过传入的配置类sample_config.ini和数据集sample_input.csv构建了一个Properties对象和一个InputProcessor对象!
然后在processInput方法中,实现下面几个功能
createTimeSeries: 将传入的csv转换为一个或多个时间序列对象
ProcessableObjectFactory.create(ts, p)
- buildTSModel : 构建时间序列模型
- buildAnomalyModel : 构建异常检测模型
- new DetectAnomalyProcessable : 用于执行异常检测的过程的对象
这一步使用到了配置文件中的几个属性:
PERIOD:指定时间序列数据的周期性,即相邻两个数据点之间的时间差
TS_MODEL:指定的时间序列模型
AD_MODEL:指定的异常检测模型
po.process(): 这个方法就是数据预测与异常检测的具体实现
public void process() throws Exception { |
数据预测
// Resetting the models |
reset(): 重置模型相关属性
train():用于训练一个基于周期性最近邻(PNN)的时间序列模型
public void train(TimeSeries.DataSequence data) {
this.data = data;
int n = data.size();
java.util.Arrays.sort(baseWindows);
java.util.Arrays.sort(timeShifts);
float precision = (float) 0.000001;
for (int i = 0; i < n; i++) {
float baseVal = Float.POSITIVE_INFINITY;
float tmpbase = (float) 0.0;
// Cannot compute the expected value if the time-series
// is too short preventing us form getting the reference
// window.
if ((i - baseWindows[0]) < 0) {
model.add(data.get(i).value);
continue;
}
// Attempt to shift the time-series.
for (int w = 0; w < baseWindows.length; w++) {
for (int j = 0; j < timeShifts.length; j++) {
if (timeShifts[j] == 0) {
tmpbase = computeExpected(i, baseWindows[w]);
if ((Math.abs(tmpbase - data.get(i).value) - Math.abs(baseVal - data.get(i).value)) < precision) {
baseVal = tmpbase;
}
} else {
if (i + timeShifts[j] < n) {
tmpbase = computeExpected(i + timeShifts[j], baseWindows[w]);
if ((Math.abs(tmpbase - data.get(i).value) - Math.abs(baseVal - data.get(i).value)) < precision) {
baseVal = tmpbase;
}
}
if (i - timeShifts[j] >= 0) {
tmpbase = computeExpected(i - timeShifts[j], baseWindows[w]);
if ((Math.abs(tmpbase - data.get(i).value) - Math.abs(baseVal - data.get(i).value)) < precision) {
baseVal = tmpbase;
}
}
}
}
}
model.add(baseVal);
}
initForecastErrors(model, data);
logger.debug(getBias() + "\t" + getMAD() + "\t" + getMAPE() + "\t" + getMSE() + "\t" + getSAE() + "\t" + 0 + "\t" + 0);
}它是OlympicModel类的一个成员方法,它需要一个参数,就是时间序列数据(data)。它会根据类中的一些参数,例如基准窗口(baseWindows),时间偏移(timeShifts),动态参数(dynamicParameters)等,来计算每个数据点的预期值,并将结果存储在一个列表(model)中。然后,它会调用initForecastErrors方法来初始化预测误差指标,并打印出来。具体的实现步骤如下:
- 首先,将时间序列数据(data)赋值给类中的一个属性(this.data),以便后续使用。
- 然后,获取时间序列数据的长度(n),并对基准窗口(baseWindows)和时间偏移(timeShifts)进行排序,以便后续遍历。
- 接着,定义一个精度值(precision),用于比较浮点数是否相等。
- 然后,遍历时间序列数据中的每个数据点(i),初始化一个最大的浮点数(baseVal)作为预期值,和一个临时变量(tmpbase)用于存储计算结果。
- 接着,判断当前数据点是否有足够长的过去数据来计算预期值,如果没有,则直接使用实际值作为预期值,并添加到列表(model)中,然后跳过当前循环,继续下一个数据点。
- 然后,尝试将时间序列数据向前或向后移动一定的时间偏移(timeShifts),并从移动后的数据中取出与当前数据点相同位置的值,作为过去的数据。对于每个过去的数据,调用computeExpected方法来计算预期值,并将结果赋值给临时变量(tmpbase)。然后,比较临时变量(tmpbase)和最大浮点数(baseVal)与实际值的差的绝对值,如果前者更小,则将临时变量(tmpbase)赋值给最大浮点数(baseVal),表示找到了更好的预期值。
- 最后,将最大浮点数(baseVal)作为最终的预期值,并添加到列表(model)中。
- 最后,调用initForecastErrors方法来初始化预测误差指标,并打印出来。
forecast(): 这个方法主要是获取指定时间的预期值
异常检测
// Reseting the anomaly detectors |
ad.reset(): 重置检测模型的属性
ad.tune(ds): 它会根据类中的一些参数,例如误差指标(aes),自动灵敏度(sDAutoSensitivity)等,来计算每个数据点的观测值和预期值之间的误差指标,并根据K西格玛原则来确定每种误差指标的阈值,并将结果存储在一个哈希表(threshold)中。
public void tune(DataSequence observedSeries, DataSequence expectedSeries) throws Exception {
HashMap<String, ArrayList<Float>> allErrors = aes.initAnomalyErrors(observedSeries, expectedSeries);
for (int i = 0; i < (aes.getIndexToError().keySet()).size(); i++) {
// Add a new error metric if the error metric has not been
// defined by the user.
if (!threshold.containsKey(aes.getIndexToError().get(i))) {
Float[] fArray = (allErrors.get(aes.getIndexToError().get(i))).toArray(new Float[(allErrors.get(aes.getIndexToError().get(i))).size()]);
threshold.put(aes.getIndexToError().get(i), AutoSensitivity.getKSigmaSensitivity(fArray, sDAutoSensitivity));
}
}
}- 首先,调用initAnomalyErrors方法来初始化所有误差指标的列表,并将结果存储在一个哈希表(allErrors)中。initAnomalyErrors方法会遍历每个数据点,调用computeErrorMetrics方法来计算该点的观测值和预期值之间的误差指标,并将结果存储在一个数组(errors)中。然后,将这些数组按照不同的误差指标分别添加到对应的列表中,并返回这些列表组成的哈希表。
- 然后,遍历每种误差指标(i),判断是否已经有用户定义的阈值(threshold),如果没有,则调用getKSigmaSensitivity方法来根据K西格玛原则计算该种误差指标的阈值,并将结果存储在哈希表(threshold)中。getKSigmaSensitivity方法会根据自动灵敏度(sDAutoSensitivity)和误差指标列表(fArray)来计算该种误差指标的均值和标准差,并返回均值加上K倍标准差作为阈值。
ad.detect(ad.metric, ds):用于检测时间序列数据中的异常点
public IntervalSequence detect(DataSequence observedSeries,
DataSequence expectedSeries) throws Exception {
// At detection time, the anomaly thresholds shouldn't all be 0.
Float threshSum = (float) 0.0;
for (Map.Entry<String, Float> entry : this.threshold.entrySet()) {
threshSum += Math.abs(entry.getValue());
}
// Get an array of thresholds.
Float[] thresholdErrors = new Float[aes.getErrorToIndex().size()];
for (Map.Entry<String, Float> entry : this.threshold.entrySet()) {
thresholdErrors[aes.getErrorToIndex().get(entry.getKey())] = Math.abs(entry.getValue());
}
IntervalSequence output = new IntervalSequence();
int n = observedSeries.size();
for (int i = 0; i < n; i++) {
Float[] errors = aes.computeErrorMetrics(expectedSeries.get(i).value, observedSeries.get(i).value);
logger.debug("TS:" + observedSeries.get(i).time + ",E:" + arrayF2S(errors) + ",TE:" + arrayF2S(thresholdErrors) + ",OV:" + observedSeries.get(i).value + ",EV:" + expectedSeries.get(i).value);
if (observedSeries.get(i).value != expectedSeries.get(i).value &&
threshSum > (float) 0.0 &&
isAnomaly(errors, threshold) == true &&
(isDetectionWindowPoint(maxHrsAgo, windowStart, observedSeries.get(i).time, observedSeries.get(0).time) ||
(maxHrsAgo == 0 && i == (n - 1)))) {
output.add(new Interval(observedSeries.get(i).time,
i,
errors,
thresholdErrors,
observedSeries.get(i).value,
expectedSeries.get(i).value));
}
}
return output;
}- 首先,创建一个空的区间序列对象(output),用于存储异常点的信息。
- 然后,计算阈值(threshold)中所有绝对值的和(threshSum),用于判断是否有有效的阈值。
- 接着,将阈值(threshold)中的每个绝对值存储在一个数组(thresholdErrors)中,方便后续使用。
- 然后,遍历观测值序列(observedSeries)中的每个数据点(i),调用computeErrorMetrics方法来计算该点的观测值和预期值之间的误差指标,并存储在一个数组(errors)中。打印出该点的时间戳、误差指标、阈值、观测值和预期值等信息。
- 接着,判断该点是否满足以下条件,如果满足,则表示该点是一个异常点,并将其添加到区间序列对象(output)中。条件如下:
- 观测值不等于预期值;
- 阈值之和大于0;
- 误差指标超过阈值;
- 该点在检测窗口内,或者检测窗口为0且该点是最后一个数据点。
- 最后,返回区间序列对象(output),其中包含了检测出来的异常点的信息。
实战
针对实际需求,我个人采取的方法是使用数据库中存储的历史数据训练模型,然后使用MQ接收实时数据,这里需要注意的一个点是训练数据集需要足够,还有一个点就是在调用ad.tune方法时,需要传入历史数据来获取合适的误差指标,否则就需要自己指定这些指标的值.否则就会导致无法检测异常点!
// Cannot compute the expected value if the time-series |
关于配置中各个参数的说明
DETECTION_WINDOW_START_TIME: 检测窗口的起始时间,如果设置为0,则从最大允许的异常时间(MAX_ANOMALY_TIME_AGO)开始。 |
最后
上面就是关于EGADS的源码解读。我希望这篇文章能够帮助您了解EGADS的工作原理和使用方法。如果您有任何问题或建议,请随时与我联系。谢谢!😊
参考
 微信
微信- 支付宝


🎉 博客更新啦!
是不是觉得页面焕然一新?没错!为了更好的体验,我们更换了全新的主题。
旧主题年久失修 😥,而且过于花哨,所以选择了更简洁、更易用的新主题。希望大家喜欢!
我的个人站点已整合到顶部"我的站点"菜单中,欢迎访问体验!若存在无法访问的情况,可以及时反馈!✨

公众号