分布式场景解决方案
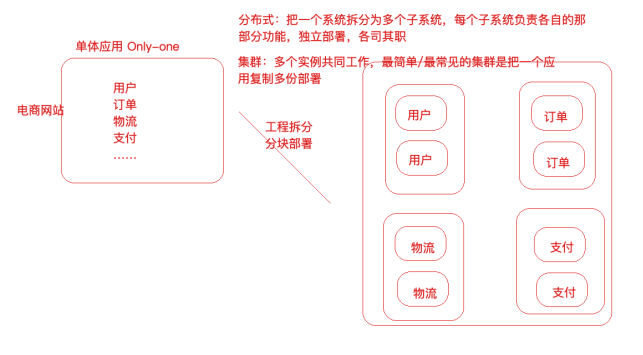
分布式与集群
一致性Hash算法
为什么要用Hash
Hash算法常用于数据存储与查找领域,最经典的就是Hash表,查询效率高,查询时间复杂度可以接近于O(1)
案例:提供一组数据1,4,6,2,7,8,如何判断n是否存在于这组数据中?
1.使用循环匹配的方式,即顺序查找法,效率不高
2.通过折半查找的方式,即二分查找法,效率依旧不高
3.创建一个数组,使用数据做下标存值,查询时,只需要判断n对应的下标是否存在值,即可判断n是否存在于数据中.即直接寻址法
4.直接寻址法优点是可以一次查找到结果,速度块,而缺点是浪费空间,当这组数据间隔较大时,需要创建一个较大的数组,并且其中大部分空间未被使用.因此,可以将数据进行求模运算法,即除留余数法
5.但是取模运算可能出现多个同样的值出现在同一位置,造成hash冲突,这时,可以将值存在前后的空位,即开放寻址法
6.假若前后没有空位,则开放寻址法不可使用,这时我们想到使用链表,在一个位置出现多个值的时候,可以使用链表的形式进行连接.即拉链法
7.但是拉链法实际上也是依赖于hash算法,若是算法太差,会导致数据全部存在数组某个位置的链表中,导致查询效率变低.
8.因此我们使用Hash结构时,我们需要考虑到hash算法的优劣,如我们常使用的HashCode就是一种hash算法的实现.
Hash算法的应用
Hash算法在很多分布式集群产品中都有应用,比如分布式集群架构Redis,Hadoop,Nginx负载均衡,Mysql分库分表等.
归纳起来就是以下两种:
1.请求的负载均衡(比如nginx的ip_hash策略)
Nginx的IP_hash策略可以在客户端Ip不变的情况下,将其发出的请求始终路由到同一个目标服务器上,实现会话粘连.避免处理session共享问题
2.分布式存储
以分布式内存数据库Redis为例,集群中有redis1,redis2.redis3三台服务器,
那么可以通过hash处理,计算数据存储时,存储到具体的某一台服务器中.
普通Hash算法的问题
普通Hash算法存在⼀个问题,以ip_hash为例,假定下载⽤户ip固定没有发⽣改变,现在tomcat3出现 了问题,down机了,服务器数量由3个变为了2个,之前所有的求模都需要重新计算。
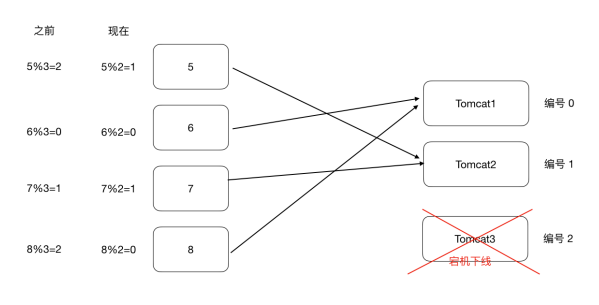
如果在真实⽣产情况下,后台服务器很多台,客户端也有很多,那么影响是很⼤的,缩容和扩容都会存 在这样的问题,⼤量⽤户的请求会被路由到其他的⽬标服务器处理,⽤户在原来服务器中的会话都会丢失.
一致性Hash算法
以0为起点,2的32次方减1作为终点构建一个圆环,针对用户和服务器ip进行hash.然后将用户分配给顺时针方向距离最近的服务器节点
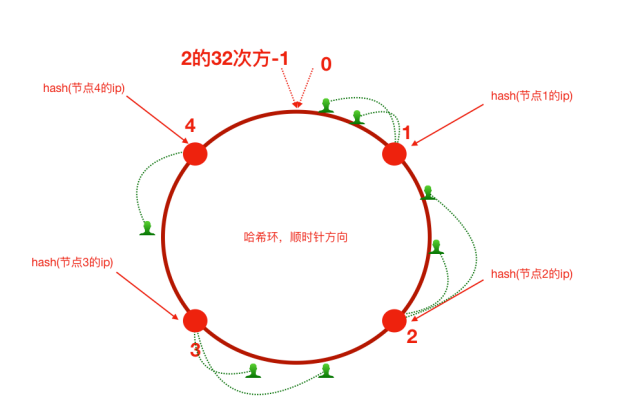
这样,当某一个服务器节点上下线时,只会影响当前区间的用户
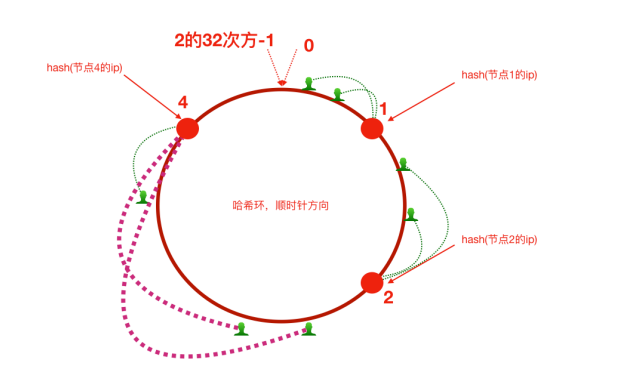
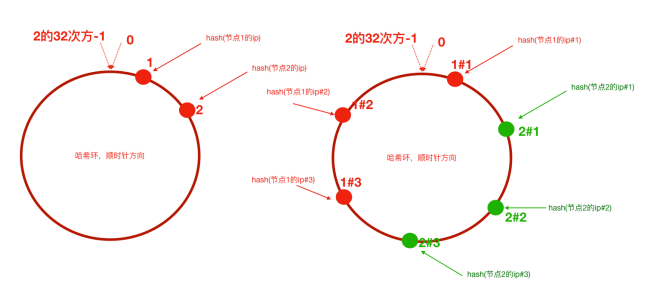
但是,当节点太少时,如两个节点,可能会导致大量的用户请求落在节点1上,造成数据倾斜问题.
为了解决数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每个服务器节点计算多次哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点
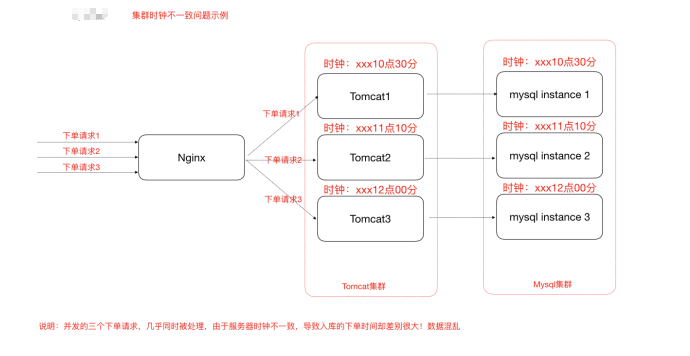
集群时钟同步问题
即集群部署时服务器时间的同步,若每个服务器的时间不一致,则将导致最终入库的数据混乱.
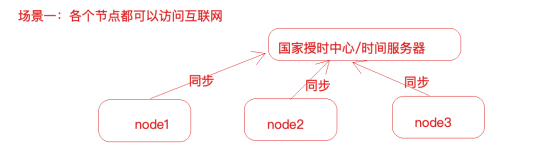
集群时钟同步思路
服务器节点能够联网
#使⽤ ntpdate ⽹络时间同步命令 |
定时执行同步命令
服务器节点不能联网
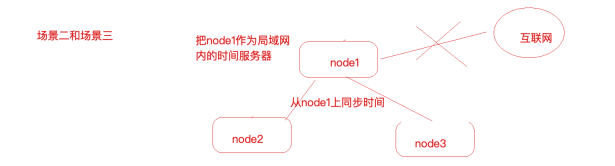
将一台服务器节点A作为时间服务器,其他服务器与此服务器保持时间同步.
1.设置好服务器节点A的时间
2.把A配置为时间服务器,修改/etc/ntp.conf文件
1、如果有 restrict default ignore,注释掉它 |
3.集群中其他节点就可以从A服务器同步时间了
ntpdate 172.17.0.17 |
分布式ID解决方案
UUID
UUID 是指Universally Unique Identifier,翻译为中⽂是通⽤唯⼀识别码 产⽣重复 UUID 并造成错误的情况⾮常低,是故⼤可不必考虑此问题
独立数据库的自增ID
⽐如A表分表为A1表和A2表,那么肯定不能让A1表和A2表的ID⾃增,那么ID怎么获取呢?我们可 以单独的创建⼀个Mysql数据库,在这个数据库中创建⼀张表,这张表的ID设置为⾃增,其他地⽅ 需要全局唯⼀ID的时候,就模拟向这个Mysql数据库的这张表中模拟插⼊⼀条记录,此时ID会⾃ 增,然后我们可以通过Mysql的select last_insert_id() 获取到刚刚这张表中⾃增⽣成的ID
SnowFlake雪花算法
雪花算法是Twitter推出的⼀个⽤于⽣成分布式ID的策略。 雪花算法是⼀个算法,基于这个算法可以⽣成ID,⽣成的ID是⼀个long型.
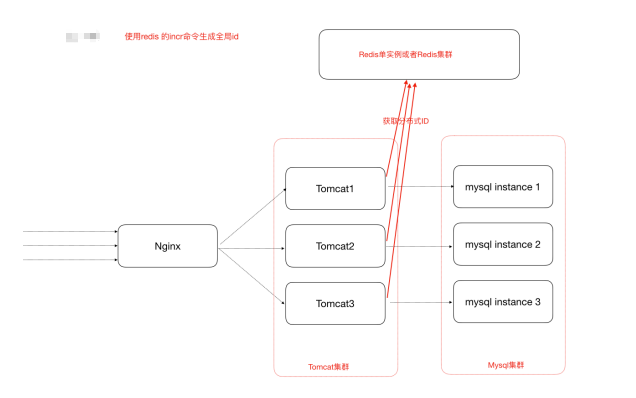
基于Redis获取
Redis Incr 命令将 key 中储存的数字值增⼀。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执⾏ INCR 操作
分布式调度问题
调度—>定时任务,分布式调度—>在分布式集群环境下定时任务这件事
Elastic-job(当当⽹开源的分布式调度框架)
定时任务的场景
定时任务形式:每隔⼀定时间/特定某⼀时刻执⾏
例如:
- 订单审核、出库
- 订单超时⾃动取消、⽀付退款
- 礼券同步、⽣成、发放作业
- 物流信息推送、抓取作业、退换货处理作业
- 数据积压监控、⽇志监控、服务可⽤性探测作业
- 定时备份数据
- ⾦融系统每天的定时结算
- 数据归档、清理作业
- 报表、离线数据分析作业
什么是分布式调度
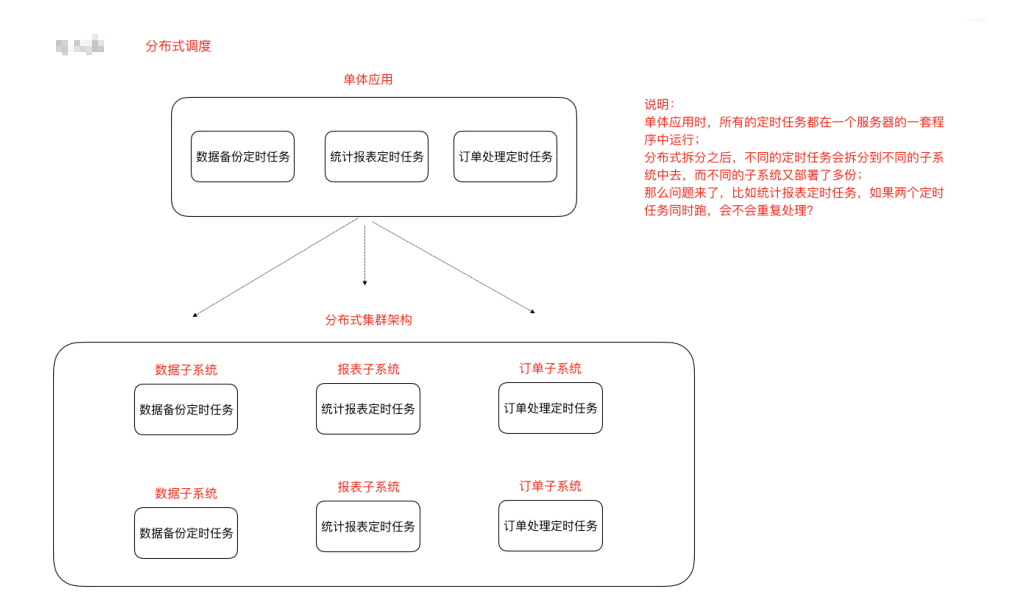
什么是分布式任务调度?有两层含义
1)运⾏在分布式集群环境下的调度任务(同⼀个定时任务程序部署多份,只应该有⼀个定时任务在执⾏)
2)分布式调度—>定时任务的分布式—>定时任务的拆分(即为把⼀个⼤的作业任务拆分为多个⼩的作 业任务,同时执⾏)
定时任务与消息队列的区别
共同点
1.异步处理
⽐如注册、下单事件
2.应用解耦
不管定时任务作业还是MQ都可以作为两个应⽤之间的⻮轮实现应⽤解耦,这个⻮轮可以中转数据,当然单体服务不需要考虑这些,服务拆分的时候往往都会考虑
3.流量削峰
双⼗⼀的时候,任务作业和MQ都可以⽤来扛流量,后端系统根据服务能⼒定时处理订单或者 从MQ抓取订单抓取到⼀个订单到来事件的话触发处理,对于前端⽤户来说看到的结果是已经下单成功了,下单是不受任何影响的
不同点
定时任务是时间驱动,而MQ是事件驱动.
定时任务倾向于批处理,而MQ倾向于逐条处理
时间驱动是不可代替的,⽐如⾦融系统每⽇的利息结算,不是说利息来⼀条(利息到来事件)就算 ⼀下,⽽往往是通过定时任务批量计算.
定时任务的实现方式
定时任务的实现⽅式有多种。早期没有定时任务框架的时候,我们会使⽤JDK中的Timer机制和多线程机 制(Runnable+线程休眠)来实现定时或者间隔⼀段时间执⾏某⼀段程序;后来有了定时任务框架,⽐ 如⼤名鼎鼎的Quartz任务调度框架,使⽤时间表达式(包括:秒、分、时、⽇、周、年)配置某⼀个任 务什么时间去执⾏;
Quartz
使用步骤
1.引入jar
<!--任务调度框架quartz--> |
2.定时任务主调度程序
package quartz; |
3.定义一个job,需要实现Job接口
package quartz; |
Elastic-Job
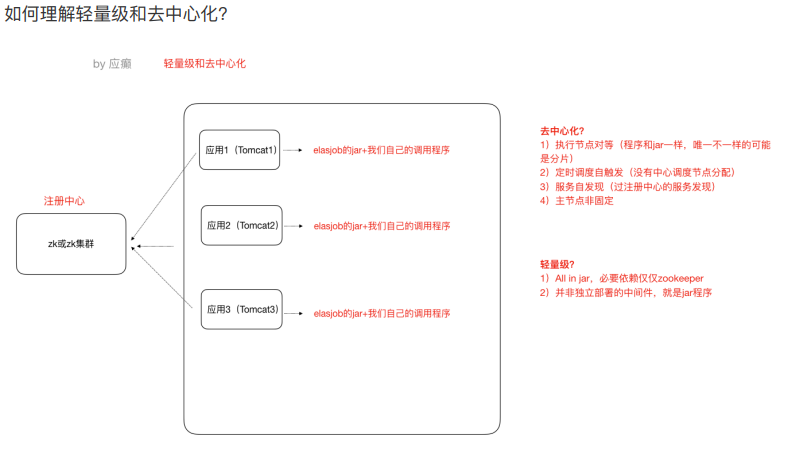
Elastic-Job是当当⽹开源的⼀个分布式调度解决⽅案,基于Quartz⼆次开发的,由两个相互独⽴的⼦项 ⽬Elastic-Job-Lite和Elastic-Job-Cloud组成。我们要学习的是 Elastic-Job-Lite,它定位为轻量级⽆中⼼ 化解决⽅案,使⽤Jar包的形式提供分布式任务的协调服务,⽽Elastic-Job-Cloud⼦项⽬需要结合Mesos 以及Docker在云环境下使⽤。
原理
基于Zookeeper的Leader节点选举机制
每个Elastic-Job的任务执⾏实例App作为Zookeeper的客户端来操作ZooKeeper的znode
(1)多个实例同时创建/leader节点
(2)/leader节点只能创建⼀个,后创建的会失败,创建成功的实例会被选为leader节点, 执⾏任
任务分片
⼀个⼤的⾮常耗时的作业Job,⽐如:⼀次要处理⼀亿的数据,那这⼀亿的数据存储在数据库中,如果 ⽤⼀个作业节点处理⼀亿数据要很久,在互联⽹领域是不太能接受的,互联⽹领域更希望机器的增加去 横向扩展处理能⼒。所以,ElasticJob可以把作业分为多个的task(每⼀个task就是⼀个任务分⽚),每 ⼀个task交给具体的⼀个机器实例去处理(⼀个机器实例是可以处理多个task的),但是具体每个task 执⾏什么逻辑由我们⾃⼰来指定。
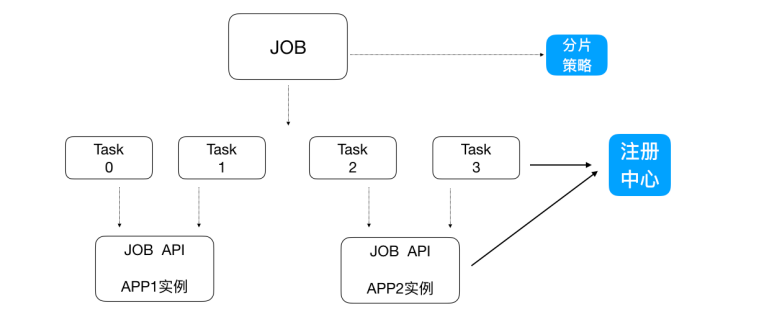
弹性扩容
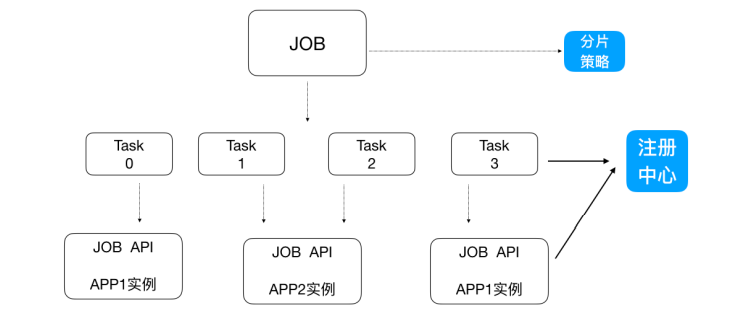
新增加⼀个运⾏实例app3,它会⾃动注册到注册中⼼,注册中⼼发现新的服务上线,注册中⼼会通知 ElasticJob 进⾏重新分⽚,那么总得分⽚项有多少,那么就可以搞多少个实例机器,⽐如完全可以分1000⽚
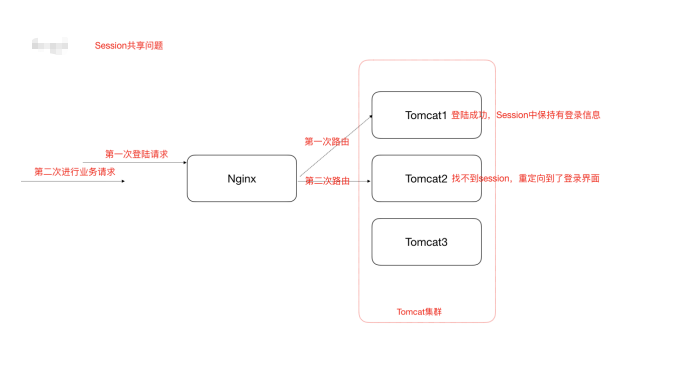
Session共享问题
多服务器之间的Session同步问题
解决方案
Nginx的IP_Hash策略(可以使用)
同⼀个客户端IP的请求都会被路由到同⼀个⽬标服务器,也叫做会话粘滞
优点
配置简单,不入侵应用,不需要额外修改代码
缺点
1.服务器重启session丢失
2.存在单点负载高的风险
3.单点故障问题
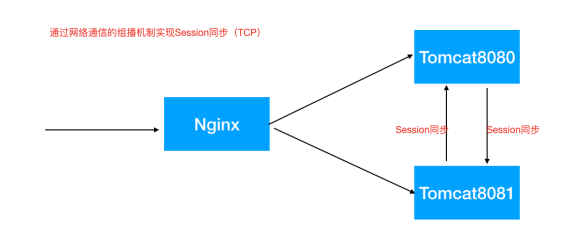
Session复制(不推荐)
多个tomcat之间修改配置文件,达到Session之间的同步
优点
1.不入侵应用
2.便于服务器水平扩展
3.能适应各种负载均衡策略
4.服务器重启或者宕机不会造成Session丢失
缺点
1.性能低
2.内存消耗
3.不能存储太多数据,否则容易影响性能
4.延迟性
Session共享,Session集中存储(推荐)
使用缓存中间件存储Session,如Redis
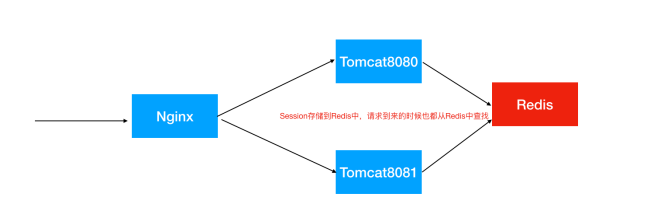
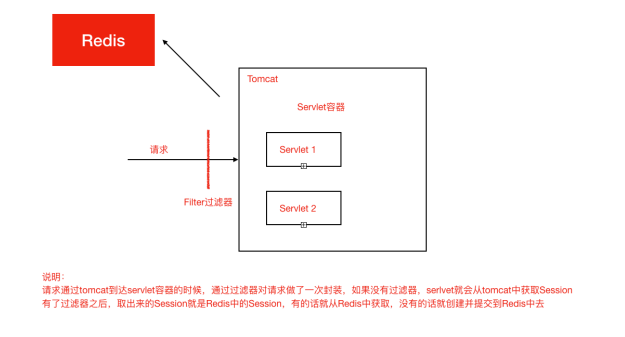
优点
1.能适应各种负载均衡策略
2.服务器宕机不会造成Session丢失
3.扩展能力强
4.适合大集群使用
缺点
对应用有入侵,引入了Redis的交互代码
使用
1.引入jar
<dependency> |
2.配置redis
spring.redis.database=0 |
3.添加注解

 微信
微信- 支付宝






🎉 博客更新啦!
是不是觉得页面焕然一新?没错!为了更好的体验,我们更换了全新的主题。
旧主题年久失修 😥,而且过于花哨,所以选择了更简洁、更易用的新主题。希望大家喜欢!
我的个人站点已整合到顶部"我的站点"菜单中,欢迎访问体验!若存在无法访问的情况,可以及时反馈!✨

公众号