
ChatGPT 第一个字慢的秘密
用 ChatGPT 或 Claude 的时候,我注意到一个现象:第一个字总要顿一下,后面就丝滑得像德芙。以前以为是网络问题,或者服务器在”热身”。
今天读到的一篇文章,才意识到这是故意的。不是 bug,是个精妙的工程技巧,叫 KV Caching。
文章开头就点破了我观察到的现象,然后一层层拆解。我跟着作者的思路走,中间有几次”啊哈”的感觉。
第一个顿悟是:大模型写字,是一个字一个字蹦的。
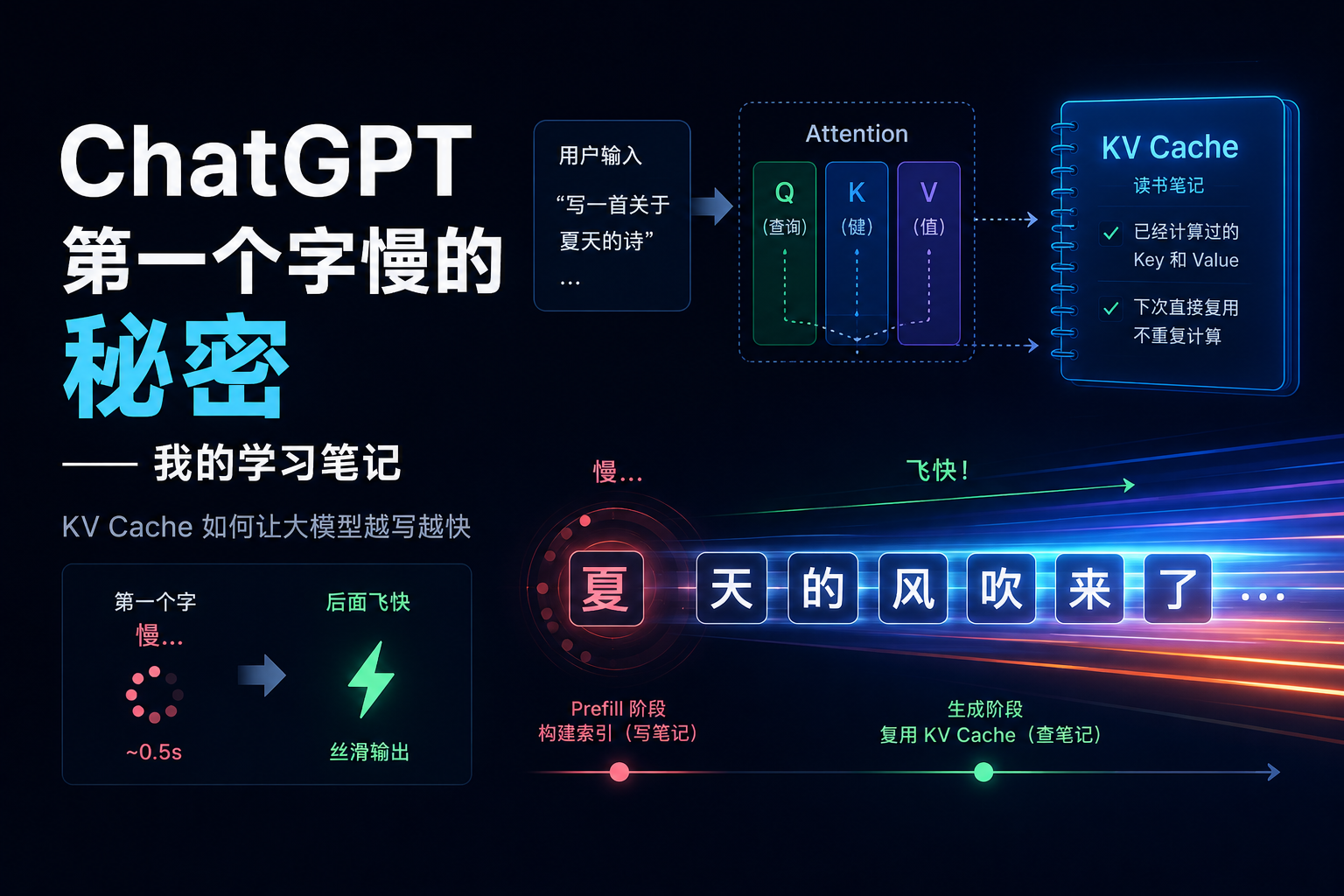
你问它”写一首关于夏天的诗”,它不是说一口气想好全诗再给你。它是先想好第一个字,给你;然后把第一个字加上你原来的问题,再想好第二个字,给你;以此类推。
这就引出一个问题:每写一个新字,都要回头看一遍全文吗?
想象一下,你正在写一篇长文章,每写一个新句子,都要从第一段第一个字开始重新读一遍全文。这得多累?而且越往后越长,越来越慢。
这就是没有 KV Cache 时的状态。
图书馆的比喻
文章用了一个技术术语来解释怎么解决:Attention(注意力机制)。我试着翻译成自己能理解的话。
想象你在图书馆找资料。你不是一本一本翻,而是有个系统:
- 你提出一个问题(Query)
- 每本书有个标签(Key)
- 书里有具体内容(Value)
系统拿你的问题去比对所有标签,找到相关的书,把内容摘出来给你。
大模型每次生成新字的时候,就是在做这件事:用最新的那个字当”问题”,去查之前所有字的”标签和内容”。
之前那些字的”标签和内容”,每次都一样啊!只要输入没变,算出来的结果就不会变。
那干嘛每次都重新算?存起来不就行了。
KV Cache 就是”读书笔记”
这就是 KV Cache 的核心:把算过的 Key 和 Value 存起来,下次直接用。
具体来说:
- 第一次处理你的长问题时(这叫 prefill 阶段),模型会算出所有字的 K 和 V,存进缓存
- 之后每生成一个新字,只需要算这个新字的 K 和 V,然后和缓存里的旧的放一起,跑一遍 Attention
- 省掉了重复计算,速度提升 5 倍左右
所以现在回头看那个”第一个字慢”的现象:那 0.5 秒左右的延迟,其实是模型在疯狂建索引、写读书笔记。一旦笔记建好了,后面就查笔记就行,飞快。
代价是什么?
文章还提到了这个设计的代价,这点让我印象很深。
内存。
每存一个字的 K 和 V,都要占 GPU 显存。上下文越长,缓存越大。对于大模型和长序列,单个请求的 KV Cache 能吃掉好几个 GB。
这就解释了另一件事:为什么上下文长度 doubled,服务器压力会大增。不是算力不够,是内存不够了。能同时服务的用户变少了。
文章提到现在有一些优化方案,比如 GQA( grouped-query attention)和 MQA(multi-query attention),就是让多个查询共享同一套 Key/Value,省内存。还有 Paged Attention 这种更底层的优化。
这些我没完全看懂,但大概知道方向:大家都在想办法,在”快”和”省内存”之间找平衡。
感受
这种工程细节很迷人。空间换时间,这是计算机科学里永恒的策略,但每次看到具体案例还是会觉得巧妙。
原文有个细节我特别喜欢:作者说 KV Caching “eliminates redundant computation”。确实如此,好的工程不就是在消灭各种冗余吗?
参考来源
 微信
微信- 支付宝



🎉 博客更新啦!
是不是觉得页面焕然一新?没错!为了更好的体验,我们更换了全新的主题。
旧主题年久失修 😥,而且过于花哨,所以选择了更简洁、更易用的新主题。希望大家喜欢!
我的个人站点已整合到顶部"我的站点"菜单中,欢迎访问体验!若存在无法访问的情况,可以及时反馈!✨

公众号


