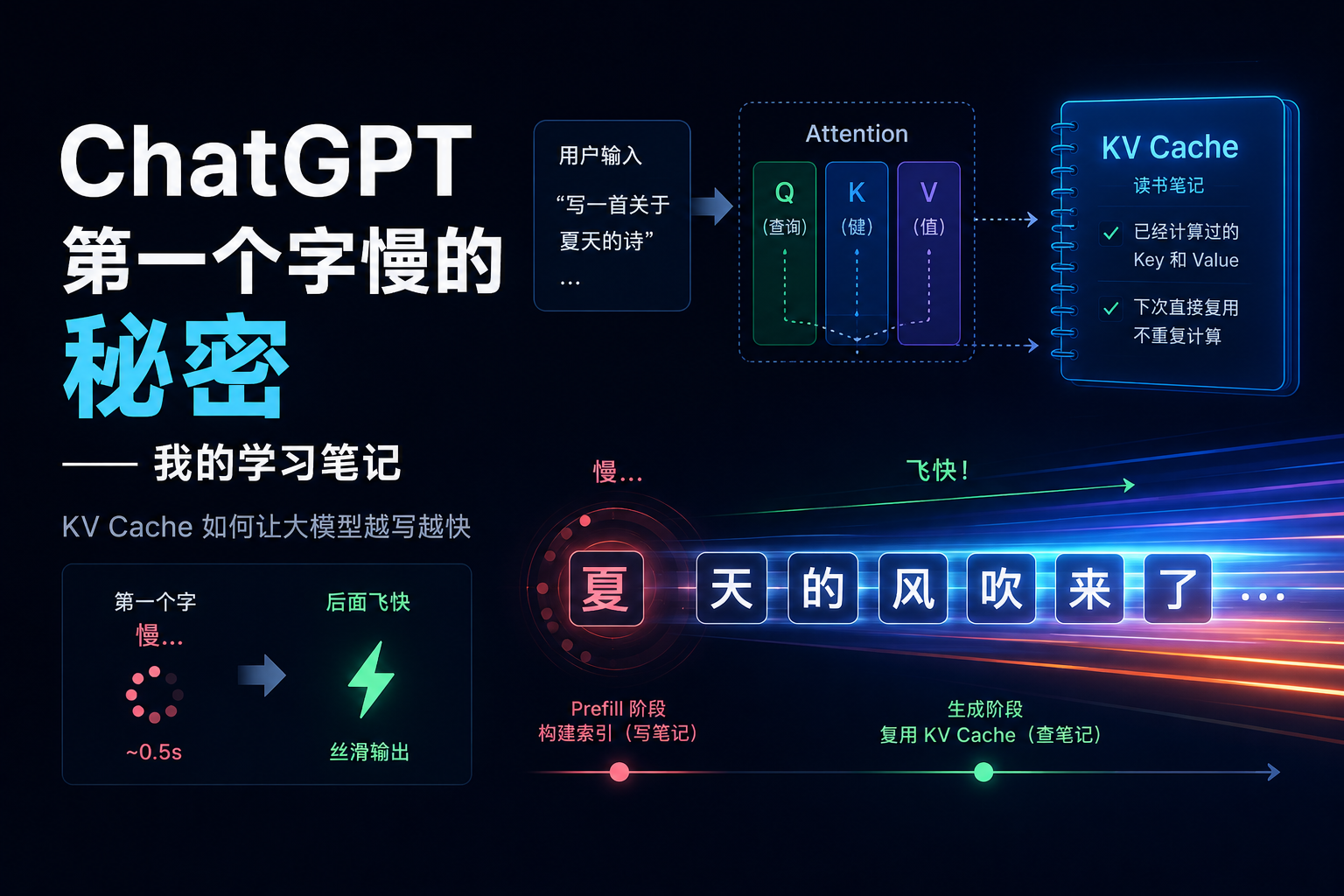
从对齐到执行:grill-me + goal,AI 编码的完整工作流

先想清楚,再放手让 agent 跑
上一篇文章聊了 Matt Pocock 的 grill-me skill——用三句话让 agent 像一个严格的 reviewer 一样,把你的方案逐个分支追问到底。它解决的是 AI 编码最核心的问题:对齐。
但对齐只是第一步。你花了半小时被灵魂拷问、做完了决策、写好了 PRD,然后呢?还是得一句一句地跟 agent 说”接下来做这个”、”继续”、”跑一下测试”、”再改改”。
这就像你跟一个新同事把需求讲得清清楚楚,然后每十分钟去他工位上说一句”干完了吗”。
最近Codex和 Claude Code填上了这个缺口,请更新到最新版。 它们同时推出了 /goal 命令——你给 agent 一个明确的目标,它自己循环执行,直到完成或碰到需要你决策的阻塞点。
Grill-me 让你想清楚,/goal 让你放手。这两件事串起来,才是 AI 编码的完整工作流。
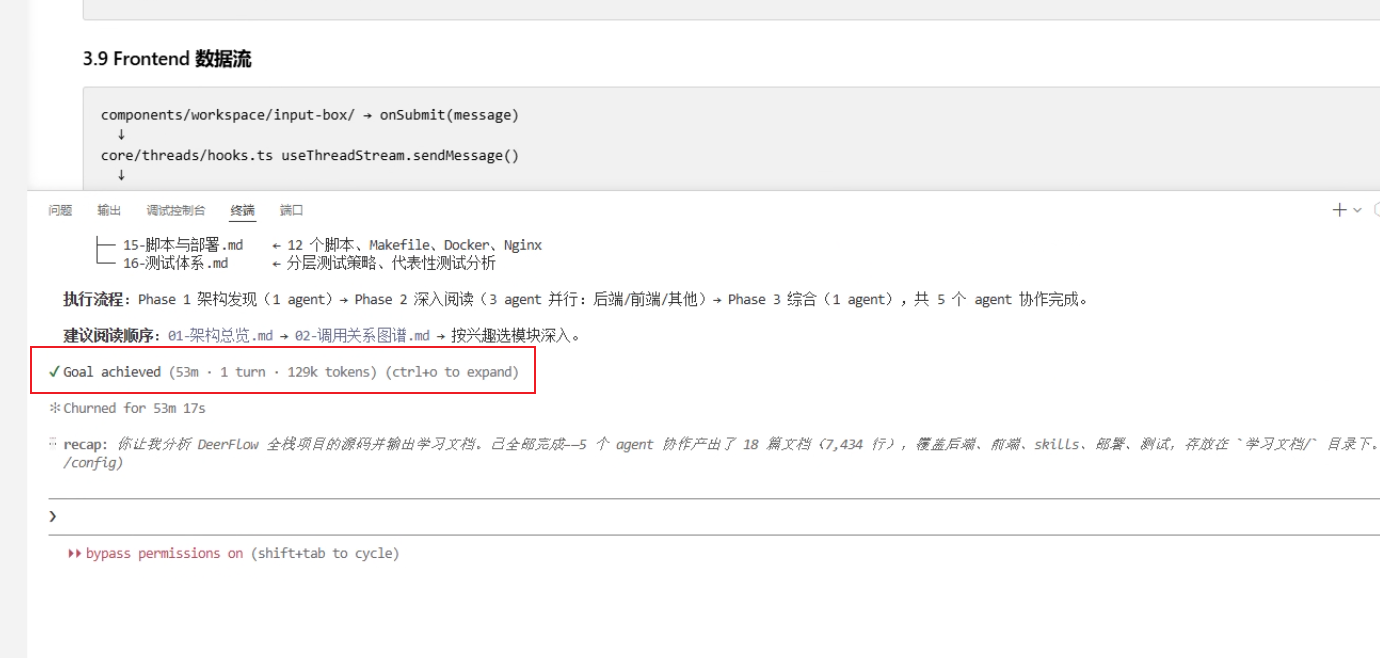
下面可以看到,我的一个任务跑了50多分钟,我的这些CLI都是运行在服务器上的,意味着以后我只需要每天设置好任务,就可以让AI 24小时帮我去干活了!
/goal 到底是什么
一句话:/goal 是一个持久化的执行目标,agent 会自主循环工作直到目标达成。
以前的交互模式是:
你:帮我修复搜索功能的 bug |
每一步都要你盯着、你推着。agent 做完一件事就停下来等你指示。
/goal 改变了这个模式:
/goal 修复搜索功能的 bug,直到所有测试通过且性能不退化 |
它不是”让 agent 在后台跑”那么简单。它有完整的生命周期管理:
- 状态机:pursuing → paused / achieved / unmet / budget-limited
- 预算控制:token 预算耗尽时优雅退出,不会乱花钱
- 证据审计:agent 不能自己说”搞定了”就搞定,必须基于实际的测试结果、代码变更等证据
- 暂停/恢复:
/goal pause暂停,/goal resume继续,不丢失上下文
两个平台如何开启?
Codex 的 /goal
Codex CLI 0.128.0 首先推出了 /goal,背后是一个叫 “Ralph loop” 的模式——agent 在紧密的循环中工作,每次迭代读取当前状态、执行一个有界的动作、写下结果、退出,然后运行时检查是否继续。
启用方式(目前需要手动开启 feature flag):
# ~/.codex/config.toml |
用法:
# 设定目标 |
Codex 的实现有一个关键设计:completion 必须基于证据。agent 不能因为”我觉得差不多了”就标记完成。它必须对比目标和实际的文件变更、测试输出、benchmark 结果等具体证据,才能宣布达成。
Claude Code 的 /goal
Claude Code 2.1.139 紧随其后加入了 /goal,功能几乎对齐:
- 交互模式:直接在 CLI 里用
/goal -p模式:脚本化调用,适合 CI/CD- Remote Control:远程会话中使用
Claude Code 的 /goal 还集成了 token 用量的实时显示——你可以看到 agent 跑了多少 token、花了多长时间、进行了几轮迭代。如果发现 token 在烧但没进展,说明 agent 陷入了循环,该手动介入了。
怎么写一个好的 Goal
不是所有任务都适合 /goal。OpenAI 的官方指南给了一个清晰的判断标准:
适合 /goal 的:下一步取决于当前学到了什么的任务。比如 debug、性能优化、依赖迁移、flaky test 调查——你不知道具体要跑几步,但你知道什么时候算完成。
不适合 /goal 的:一步就能搞定的事。改个变量名、加个注释、读一段代码——直接用普通 prompt 就行。
一个好的 Goal 应该包含六件事:
- 目标:什么状态算完成
- 验证方式:用什么证据来证明完成
- 约束:什么东西不能退化
- 边界:只能动哪些文件/工具
- 迭代策略:下一步怎么选
- 阻塞处理:卡住了怎么办
对比一下:
弱的 Goal:
/goal 修复搜索的 bug |
(agent 不知道”修复”的定义是什么,不知道怎么验证,可能改了代码但没跑测试就宣布成功)
强的 Goal:
/goal 修复搜索功能中中文分词返回空结果的问题,验证标准是所有搜索相关测试通过且 |
(agent 知道什么算成功、怎么验证、不能动什么、卡住了怎么办)
串起来:从对齐到执行的完整流程
这是我觉得最有价值的部分。grill-me 和 /goal 不是两个独立的工具,它们是同一个工作流的两个阶段。
第一步:用 grill-me 想清楚
/grill-me 我想给搜索功能加上模糊匹配能力 |
agent 会开始追问:
- 模糊匹配的容错级别是什么?一个字的错别字还是整个词?
- 用什么算法?Levenshtein?Jaccard?还是 Elasticsearch 的 fuzzy query?
- 响应时间要求是多少?
- 中文和英文的处理方式一样吗?
- 是在现有搜索结果上加一层,还是作为独立的搜索模式?
- 需要高亮匹配部分吗?
每个问题都给出推荐答案,你只需要确认或调整。跑完一遍之后,你对要做的事情有了清晰的、完整的认知。
第二步:用 /goal 自动执行
grill-me 跑完之后,你已经知道所有答案了。直接写 Goal:
/goal 给搜索功能加上模糊匹配能力。具体要求: |
然后就放手让 agent 跑。它会自己分析代码、设计方案、写代码、跑测试、修复问题、再测试,直到全部通过。
完整流程对比
以前:
- 想个大概的方案
- 直接让 agent 写
- 看到结果不对,告诉 agent 改
- 来回折腾 10 轮
- 最后勉强能用,但很多细节是妥协的结果
现在:
- grill-me 被追问 20 个问题,想清楚每个细节
- /goal 设定明确目标和验证标准
- agent 自己跑,你去做别的事
- 回来看结果,跑通了就收货
注意事项
token 消耗会更大。 /goal 的本质是让 agent 多跑很多轮,每轮都有 token 开销。特别是复杂任务,几百 K token 很正常。设好预算,盯着用量。
不是所有 agent 都适合自主循环。 如果你的项目很乱、测试覆盖很差、没有明确的验证手段,/goal 可能会跑偏。先把这些基础设施补上。
grill-me 的价值在于它强迫你精确。 很多人觉得”我大概知道要做什么”就够了,但 agent 需要的是精确的、无歧义的目标。grill-me 帮你把”大概”变成”确定”。
写在最后
2026 年的 AI 编码工具越来越像一个完整的工程系统,而不只是”帮我写代码”的自动化。grill-me 和 /goal 代表了两个方向:对齐的深度和执行的自主性。
把这两个指令组合起来,你得到的不是”更快的代码生成”,而是一个真正能独立完成工程任务的 agent。你负责决策,它负责执行。
这可能才是 AI 编码该有的样子。
 微信
微信- 支付宝








🎉 博客更新啦!
是不是觉得页面焕然一新?没错!为了更好的体验,我们更换了全新的主题。
旧主题年久失修 😥,而且过于花哨,所以选择了更简洁、更易用的新主题。希望大家喜欢!
我的个人站点已整合到顶部"我的站点"菜单中,欢迎访问体验!若存在无法访问的情况,可以及时反馈!✨

公众号