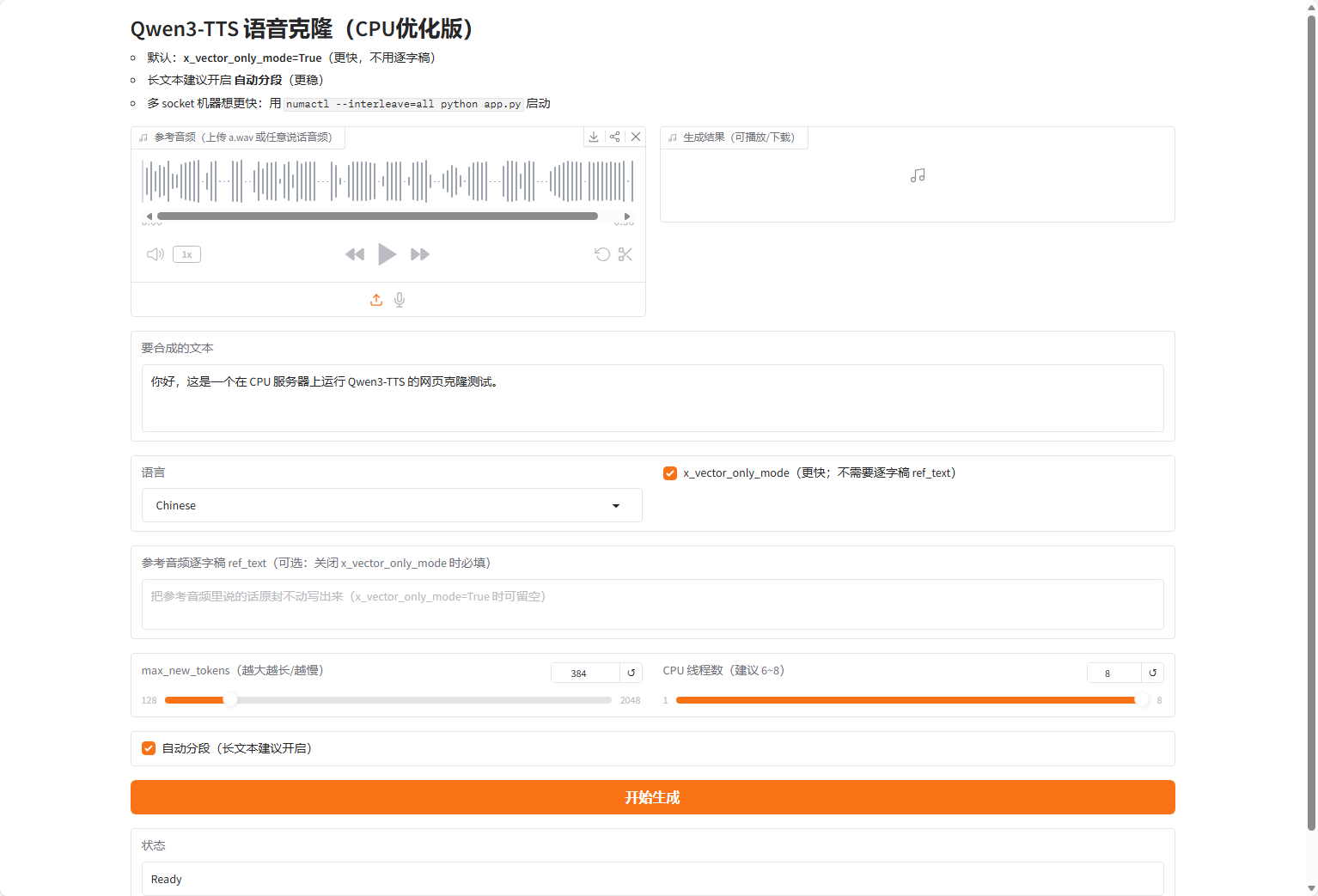
用自己的声音让 AI 读稿,我以前就有这个想法!
之前试过 ElevenLabs,效果确实好,但每个月 10 美元起步,用多了还得加钱。Azure 的 TTS 便宜点,但声音克隆要企业认证,个人用户压根申请不下来。开源方案倒是有,CosyVoice、FishSpeech 都不错,问题是我那台老笔记本只有 8GB 显存,跑这俩都费劲。
直到上周,阿里把 Qwen3-TTS 全家桶开源了。
0.6B 有多轻量? 0.6B 模型只需要 1.2GB 显存 ,没有独显的话,纯 CPU 也能跑。
这意味着什么?一台普通办公电脑,8GB 内存,集显,就能跑完整的语音合成模型。不用买云服务器,不用按量付费,模型下到本地,想用多少用多少。我特地用一台普通云电脑跑了下,慢是慢了点,但是能用!
Qwen3-TTS 这次开源了两个尺寸:
模型
参数量
显存需求
定位
1.7B
17 亿
~3.4GB
极致音质
0.6B 6 亿
~1.2GB 均衡效率
0.6B 虽然参数少,但该有的能力都有:10 种语言(中英日韩德法俄葡西意)、多种方言(粤语、四川话、闽南语等)、声音克隆、声音设计。对于个人用户来说,0.6B 已经够用了。
安装
https://github.com/QwenLM/Qwen3-TTS
这块直接看官方文档吧! 或者让AI给你安装就行,留一份我的一键脚本,可以自己试试!
装完之后,第一次运行会自动下载模型权重,0.6B 大概 1.2GB,耐心等一下。
#!/usr/bin/env bash set -euo pipefailROOT="/wangwang/qwen" MODEL_ID="Qwen/Qwen3-TTS-12Hz-0.6B-Base" mkdir -p "$ROOT " cd "$ROOT " echo "[1/6] venv" python3 -m venv .venv source .venv/bin/activatepython -m pip install -U pip wheel setuptools echo "[2/6] HF mirror + cache" export HF_ENDPOINT="https://hf-mirror.com" export HF_HOME="$ROOT /hf_home" echo "[3/6] PyTorch (CPU wheel)" pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu echo "[4/6] Runtime deps" pip install -U "qwen-tts" "huggingface_hub[cli]" soundfile requests numpy echo "[5/6] CPU performance knobs" THREADS="${THREADS:-$(python - <<'PY' import os n=os.cpu_count() or 1 print(max(1, min(8, n))) PY )} "export OMP_NUM_THREADS="$THREADS " export MKL_NUM_THREADS="$THREADS " export OPENBLAS_NUM_THREADS="$THREADS " export NUMEXPR_NUM_THREADS="$THREADS " echo "THREADS=$THREADS " echo "[6/6] Smoke test (voice clone -> out/output_voice_clone.wav)" mkdir -p outpython - <<'PY' import io, os, requests import numpy as np import torch import soundfile as sf from qwen_tts import Qwen3TTSModel MODEL_ID="Qwen/Qwen3-TTS-12Hz-0.6B-Base" threads = int(os.environ.get("OMP_NUM_THREADS" ,"4" )) torch.set_num_threads(threads) torch.set_num_interop_threads(1) print ("torch:" , torch.__version__)print ("threads:" , threads)ref_audio_url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone.wav" resp = requests.get(ref_audio_url, timeout =60) resp.raise_for_status() wav, sr = sf.read(io.BytesIO(resp.content)) if wav.ndim > 1: wav = np.mean(wav, axis=1) wav = wav.astype(np.float32) ref_audio = (wav, int(sr)) ref_text = "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you." tts = Qwen3TTSModel.from_pretrained( MODEL_ID, device_map="cpu" , dtype=torch.float32, attn_implementation="eager" , ) wavs, out_sr = tts.generate_voice_clone( text="Hello! This is a CPU smoke test for Qwen3-TTS voice cloning." , language="English" , ref_audio=ref_audio, ref_text=ref_text, x_vector_only_mode=False, max_new_tokens=768, ) sf.write("out/output_voice_clone.wav" , wavs[0], out_sr) print ("Saved -> out/output_voice_clone.wav | sr:" , out_sr, "| sec:" , len(wavs[0])/out_sr)PY echo "DONE: $ROOT /out/output_voice_clone.wav"
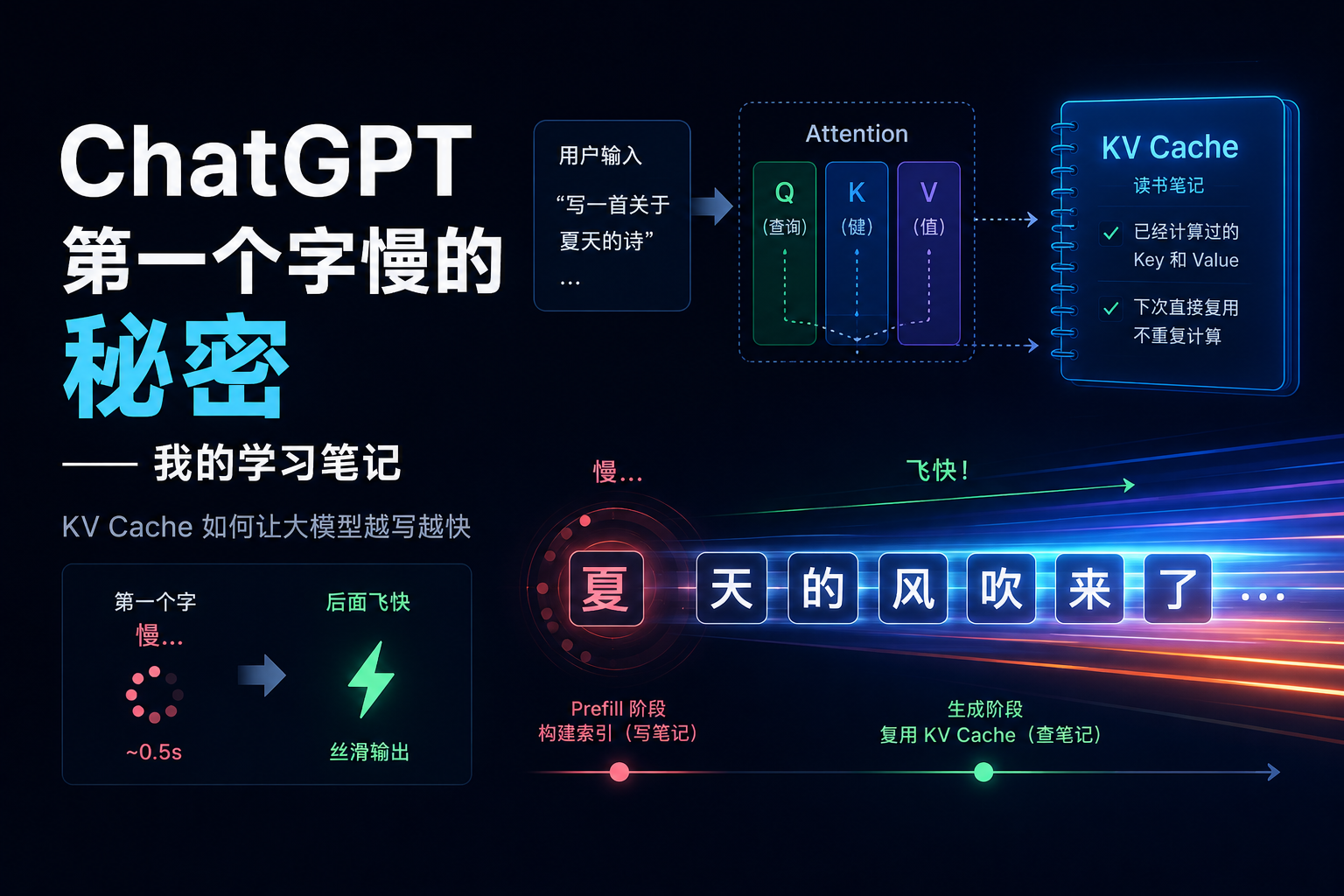
声音克隆:3 秒音频就够 这是 Qwen3-TTS 最让我意外的功能。只需要一段 3-10 秒的音频,模型就能学会这个人的音色、语调、说话节奏,然后用这个声音读任何你给的文本。
代码也不复杂:
import torchimport soundfile as sffrom qwen_tts import Qwen3TTSModelmodel = Qwen3TTSModel.from_pretrained( "Qwen/Qwen3-TTS-12Hz-0.6B-Base" , device_map="cuda:0" , dtype=torch.float16, ) wavs, sr = model.generate_voice_clone( text="今天天气不错,适合出去走走。" , language="Chinese" , ref_audio="my_voice.wav" , ref_text="这是参考音频的文字内容。" , ) sf.write("output.wav" , wavs[0 ], sr)
我拿自己录的一段 5 秒音频试了试,效果出乎意料。音色还原度很高,连我说话时习惯性的尾音拖长都学到了。想效果更好的话可以换 1.7B,代价是显存占用翻倍。
有个坑:ref_text 参数是必须的,你得告诉模型参考音频里说了什么。懒得写的话可以开 x_vector_only_mode,只用音色特征不看文本,但音质会打折扣。
封装成 Claude Code Skill 上面说的都是官方玩法,接下来是我自己折腾出来的骚操作。
既然 Qwen3-TTS 可以本地运行,那能不能封装成一个服务,随时调用?更进一步,能不能做成 Claude Code 的 Skill,让 AI 助手直接帮我把文字转成语音?
答案是可以的。而且一旦配好,就相当于有了一个无限免费的私人 TTS 服务 。
为什么要这么做? 每次用 TTS 都要手动跑 Python 脚本,麻烦。封装成 Skill 之后,直接在 Claude Code 里敲 /qwen-tts 今天天气不错,AI 就能帮你生成语音文件。写文章的时候想听听读起来顺不顺口?一句命令搞定。有需要的用户可以留言,我可以将自己的分享到github上!
然后修改 Skill,让它调用这个 API 而不是每次都加载模型。这样响应速度能从十几秒缩短到一两秒。
适合什么人用?
内容创作者 :写公众号、做视频,需要配音但不想花钱开发者 :想在自己的应用里加入语音功能,不想被 API 账单吓到折腾党 :就是想在本地跑个 AI 玩玩,不需要理由
如果你追求极致音质,愿意等更长的生成时间,可以换成 1.7B 模型。如果你的电脑配置一般,或者更看重响应速度,0.6B 是更实际的选择。
最后 阿里这次开源的 Qwen3-TTS,给了我一点惊喜。0.6B 这个尺寸,在保持可用性的前提下,把硬件门槛拉到了普通用户能接受的水平。声音克隆不再是云端大厂的专利,一台普通电脑就能玩。
更重要的是,它是 Apache 2.0 协议,商用也没问题。
GitHub 地址:https://github.com/QwenLM/Qwen3-TTS
Hugging Face 在线体验:https://huggingface.co/spaces/Qwen/Qwen3-TTS
有兴趣的话,去试试用自己的声音做一个 AI 分身。




 微信
微信