《程序是怎么跑起来的》阅读笔记
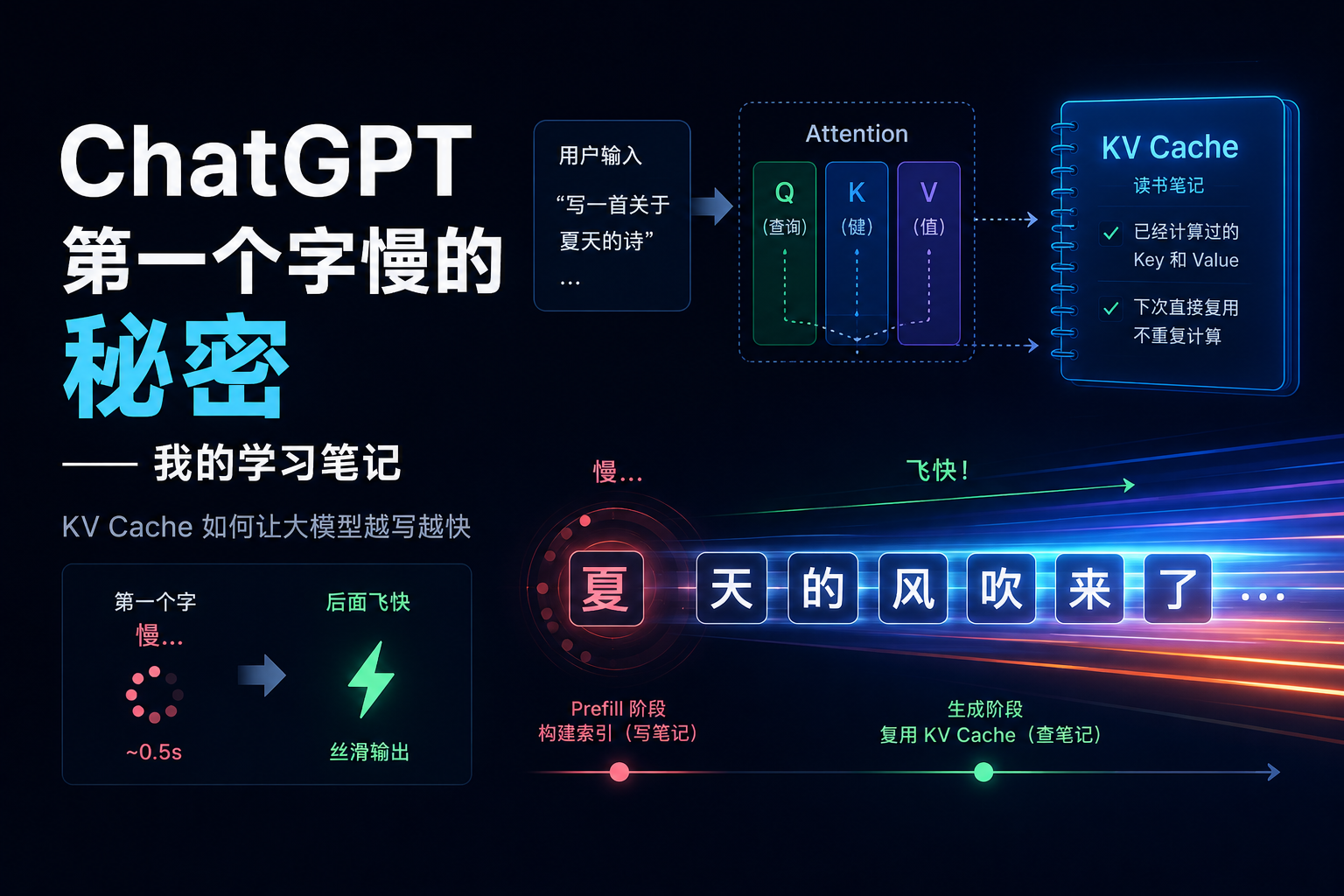
CPU内部结构
1.寄存器: 用来暂存指令,数据等处理对象
2.控制器: 负责把内存上的指令,数据读入寄存器,并根据指令执行结果来控制整个计算机
3.运算器: 负责从内存读入寄存器的数据
4.时钟: 负责发出CPU开始计时的时钟信号
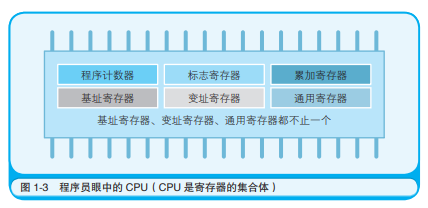
程序计数器
1.程序计数器: 是决定程序流程的寄存器,它指向下一条执行的指令
2.程序流程: 顺序执行,条件分支,循环
3.程序中的比较指令,就是在CPU内部做减法运算
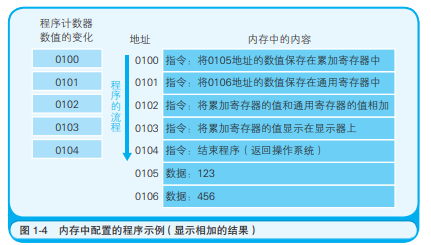
4.函数调用机制
二进制
1.IC的所有引脚,只有直流电压的0v和5v两个状态,这也是二进制的由来.它只有0和1两种数字。
2.计算机处理信息的最小单位为位,一个字节等于8位
3.二进制和十六进制之间可以进行相互转换,每4位二进制数对应1位十六进制数。
4.Java中可以用0b或0B开头表示二进制数,用0x或0X开头表示十六进制数。

运算
1.移位运算符有两种:左移运算符(<<)和右移运算符(>>),分别表示将一个数的各二进制位向左或向右移动若干位。
2.移位运算中,无符号数和有符号数的运算并不相同。对于无符号数,右移之后高位补0;对于有符号数,符号位一起移动,正数高位补0,负数高位补1
3.移位运算的优先级比算术运算符、关系运算符、逻辑运算符和其他运算符都低
4.表示负数时,使用的是二进制的补数,即负数的绝对值的二进制数,取反+1
逻辑右移和算术右移的区别是:
- 逻辑右移是不考虑符号位,只是将所有的二进制位向右移动,并在高位补0
- 算术右移是考虑符号位,将除了最高位之外的其他二进制位向右移动,并在高位补上原来的最高位
补码和反码是用来表示负数的方法:
- 补码是将一个负数的绝对值按照二进制形式表示出来,然后对每一位取反(即0变1,1变0),再加上1得到的结果
- 反码是将一个负数的绝对值按照二进制形式表示出来,然后对每一位取反(即0变1,1变0)得到的结果
逻辑运算: 包括逻辑非(NOT),逻辑与(AND),逻辑或(OR),逻辑异或(^)

小数运算
- 计算机进行小数运算时出错的原因是计算机内部使用二进制表示小数,而有些小数在二进制中无法精确表示,例如0.1。
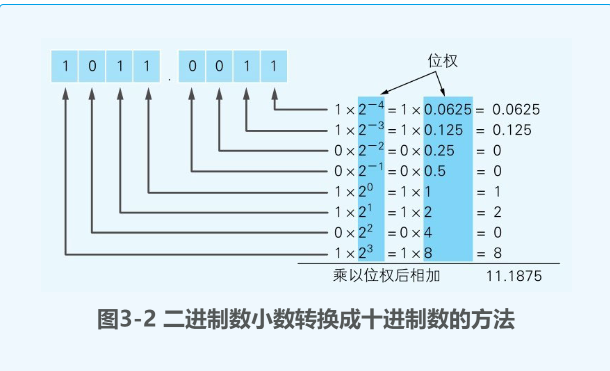
- 为了解决这个问题,计算机采用了浮点数的方式来表示小数,即将一个小数分成有效数字和指数两部分,并用固定的位数来存储它们。

- 浮点数也有一定的精度限制,因为有效数字和指数的位数是有限的。如果超出了这个范围,就会产生溢出或下溢的情况。
- 浮点数还有一些特殊的值,例如正负无穷大、非数字(NaN)和零。这些值可以用来表示一些异常或无意义的结果,例如除以零或开方负数。
- 浮点数之间的比较和运算要注意精度损失和舍入误差。为了避免这些问题,可以使用一些技巧或工具,例如设置合理的误差范围、使用高精度库或软件等。
内存
- 内存是一种电子元件,可以存储和读取数据。内存有多种类型,例如DRAM、SRAM、ROM等。
- 内存的容量和速度取决于其引脚的数量和配置。引脚分为电源、地址信号、数据信号、控制信号等,用于输入输出数据。
- 内存的地址空间是指内存可以表示的地址范围。地址空间的大小由地址信号的位数决定,例如32位地址信号可以表示2^32个地址。
- 内存的访问方式有两种:字节寻址和字寻址。字节寻址是指每个字节都有一个独立的地址,而字寻址是指每个字(通常为4个字节)都有一个独立的地址。
- 内存中的数据可以按照不同的方式排列,例如大端法和小端法。大端法是指高位字节放在低位地址,而小端法是指低位字节放在低位地址。
数据结构
- 栈和队列是两种常用的数据结构,可以对数组的元素进行不通过指定地址和索引的读写操作。
- 栈是一种后进先出(LIFO)的数据结构,只能在一端进行插入和删除操作。栈可以用来保存函数调用时的返回地址、局部变量等信息。
- 队列是一种先进先出(FIFO)的数据结构,只能在一端插入,在另一端删除。队列可以用来保存输入输出设备的数据、事件等信息。
- 环形缓冲区是一种特殊的队列,它使用一个固定大小的数组来存储数据,并通过两个指针来标记队首和队尾。环形缓冲区可以实现无缝地循环使用数组空间,避免浪费或溢出。
磁盘
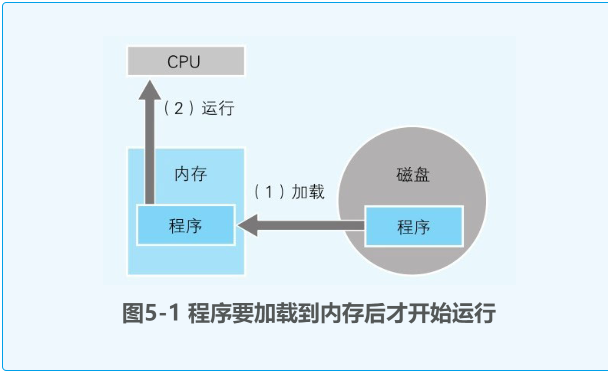
- 计算机中主要的存储部件是内存和磁盘,磁盘中存储的程序,必须要加载到内存中才能运行
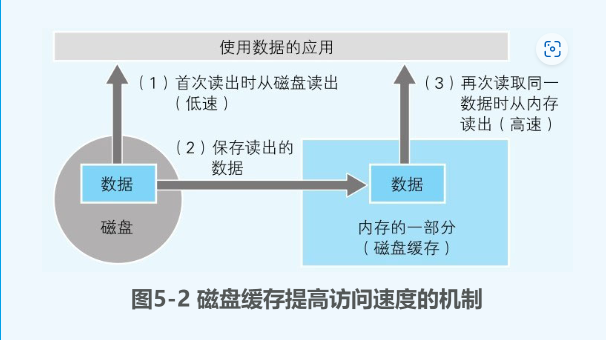
- 磁盘缓存可以大大改善磁盘数据的访问速度
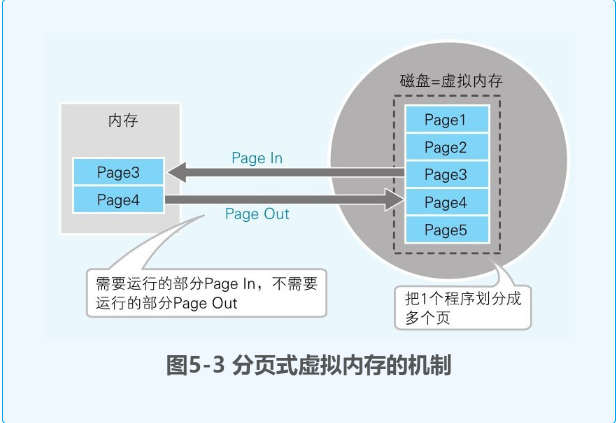
- 虚拟内存则是为了解决内存不足的情况,将磁盘的一部分作为内存来使用.在使用中实际内存和虚拟内存的内容会进行部分置换,以满足程序运行的需要
- 虚拟内存分为分页式与分段式
数据压缩
RLE算法是一种简单的无损压缩算法,它利用数据中的重复性,将连续出现的相同数据用一个计数值和一个数据值来表示。例如,AAAAABBBBCCCC可以压缩为5A4B4C。
RLE算法适合于处理有大量重复数据的文件,如图像、音频等。RLE算法的优点是压缩和解压速度快,算法简单易实现;缺点是压缩率较低,对于没有重复数据的文件无法压缩甚至可能增大文件大小。
哈夫曼编码是一种基于概率的无损压缩算法,它根据数据中每个符号出现的频率,构建一棵二叉树,给每个符号分配一个不同长度的二进制编码。出现频率高的符号分配较短的编码,出现频率低的符号分配较长的编码。例如,如果一个文件中A出现了45次,B出现了13次,C出现了12次,D出现了16次,E出现了9次,F出现了5次,则可以构建如下图所示的哈夫曼树,并给每个符号分配如下表所示的编码。
| Symbol | Frequency | Code |
|---|---|---|
| A | 45 | 0 |
| B | 13 | 101 |
| C | 12 | 100 |
| D | 16 | 111 |
| E | 9 | 1101 |
| F | 5 | 1100 |
- 哈夫曼编码适合于处理有不同频率的符号组成的文件,如文本、程序等。哈夫曼编码的优点是压缩率较高,可以达到最优压缩;缺点是压缩和解压速度较慢,需要构建和存储哈夫曼树。
系统与软件
系统是一组相互关联的部件,它们共同完成一个特定的功能或目标。系统可以分为硬件系统和软件系统。硬件系统是由物理设备组成的,如CPU、内存、硬盘等。软件系统是由程序和数据组成的,如操作系统、应用程序等。
系统可以提高效率、可靠性和安全性。例如,操作系统是一种软件系统,它管理和控制硬件资源,提供用户界面和服务,保护数据和程序不被破坏或泄露。应用程序是一种软件系统,它实现用户的需求和功能,如浏览器、游戏、办公软件等。
- 源代码是人类编写的程序语言,如Java、C、Python等。为了让计算机能够理解和执行源代码,需要经过以下几个步骤:
编译:将源代码转换为目标代码,即机器语言或汇编语言。不同的编程语言有不同的编译器,如Java有javac,C有gcc等。
链接:将多个目标代码文件和库文件合并为一个可执行文件。链接可以分为静态链接和动态链接。静态链接是在编译时进行的,将所有依赖的库文件嵌入到可执行文件中。动态链接是在运行时进行的,将依赖的库文件加载到内存中,并通过地址重定位来连接到可执行文件中。
加载:将可执行文件从磁盘加载到内存中,并分配必要的资源,如栈、堆、寄存器等。
应用是用户通过操作系统来启动和使用的软件系统。当用户运行一个应用时,操作系统会创建一个进程来表示该应用,并为其分配一个虚拟地址空间和一些其他资源。进程是操作系统管理和调度的基本单位,它包含了应用运行所需的所有信息,如程序计数器、状态寄存器、堆栈指针等。操作系统通过进程控制块(PCB)来存储进程的信息,并通过进程表来管理所有进程。操作系统还负责在多个进程之间进行切换和调度,以实现多任务和并发。
 微信
微信- 支付宝







🎉 博客更新啦!
是不是觉得页面焕然一新?没错!为了更好的体验,我们更换了全新的主题。
旧主题年久失修 😥,而且过于花哨,所以选择了更简洁、更易用的新主题。希望大家喜欢!
我的个人站点已整合到顶部"我的站点"菜单中,欢迎访问体验!若存在无法访问的情况,可以及时反馈!✨

公众号