时序性数据库InfluxDB初探与优化
简介
InfluxDB是一个由InfluxData开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据。时序型数据是指那些随时间变化而变化的数据,比如温度,湿度,股票价格,网站访问量等。这些数据通常具有高频率,高精度,高复杂度和高价值的特点。InfluxDB可以帮助我们有效地管理和分析这些数据,为我们提供实时的洞察和预测。
为了让你更好地理解InfluxDB的优势和特色,我用一个表格来比较它和MySQL等传统关系型数据库的区别:
| 特点 | InfluxDB | MySQL |
|---|---|---|
| 数据模型 | 基于时间序列的键值对 | 基于表格的行列 |
| 数据结构 | 灵活,无需预定义模式 | 固定,需要预先定义模式 |
| 数据类型 | 主要支持数值类型 | 支持多种类型 |
| 查询语言 | 使用Flux语言,专为时序型数据设计 | 使用SQL语言,通用但不针对时序型数据 |
| 写入性能 | 高效,支持批量写入和压缩存储 | 一般,需要事务处理和索引维护 |
| 查询性能 | 快速,支持多维聚合和窗口函数 | 慢速,需要多表连接和分组排序 |
| 可扩展性 | 易于水平扩展和分布式部署 | 难以水平扩展和分布式部署 |
从上表可以看出,InfluxDB比MySQL更适合处理时序型数据,因为它有更高的性能,更灵活的数据模型,更强大的查询语言和更好的可扩展性。
版本
官网: InfluxDB OSS 2.3 Documentation (influxdata.com)
如果你想更深入地了解InfluxDB的功能和用法,我强烈建议你去多看官方文档。官方文档是InfluxDB的最权威和最全面的资料来源,它包含了InfluxDB的安装,配置,管理,查询,分析,可视化等方面的详细说明和示例。官方文档还提供了一些常见问题和解决方案,以及一些最佳实践和技巧。官方文档是你学习和使用InfluxDB的最好的伙伴。
安装
配置文件
在InfluxDB中,配置文件默认是不存在的,需要执行以下命令进行生成,流入数据库配置选项 |InfluxDB OSS 2.3 文档 (influxdata.com)
docker run --rm influxdb:2.3.0 influx server-config > config.yml |
具体内容如下:
{ |
部署InfluxDB
我是基于Docker部署的InfluxDB2.3版本,docker-compose配置文件如下:
version: "3.1" |
这个文件定义了一个名为influxdb的服务,它使用influxdb:2.3这个镜像来创建一个容器,它将容器的8086端口映射到主机的8086端口,它将容器的/var/lib/influxdb2目录挂载到主机的influxdbv2这个卷上,它设置了一些环境变量来初始化InfluxDB的用户,组织,存储桶,保留策略和令牌。
配置优化
- [http]:这个部分控制了InfluxDB的HTTP服务,包括绑定地址,端口,超时时间,日志级别等。你可以根据你的网络环境和安全需求来调整这些参数。
- [storage]:这个部分控制了InfluxDB的存储引擎,包括缓存大小,快照频率,压缩策略,索引大小等。你可以根据你的硬件资源和性能需求来调整这些参数。
- [retention]:这个部分控制了InfluxDB的数据保留策略,包括检查间隔,启用状态等。你可以根据你的数据量和存储空间来调整这些参数。
- [query]:这个部分控制了InfluxDB的查询引擎,包括并发度,队列大小,内存限制等。你可以根据你的查询负载和内存资源来调整这些参数。
针对内存占用空间过大的问题,可以尝试以下方法:
- 减少写入数据的频率和精度。如果你不需要实时或高精度的数据,你可以降低写入数据的频率和精度,从而减少数据量和索引大小。
- 增加数据压缩比率。如果你不需要高速查询或写入数据,你可以增加数据压缩比率,从而减少数据占用的空间。你可以通过修改storage-compact-throughput-burst参数来调整压缩比率。
- 启用数据保留策略。如果你不需要永久保存数据,你可以启用数据保留策略,从而定期删除过期或无用的数据。你可以通过修改retention-check-interval参数来调整保留策略。
GC优化
参考: HTSI 模式内存使用率高
- GODEBUG=madvdontneed=1 |
GODEBUG=madvdontneed=1可以减少InfluxDB的虚拟内存占用,而GOGC=80可以减少InfluxDB的实际内存占用。
入门
时序型数据在InfluxDB中是以一种叫做行协议(line protocol)的格式来表示的。行协议是一种文本格式,它由四个部分组成:
- 度量(measurement):表示数据的类别或名称,比如温度,湿度,电压等。
- 标签(tag):表示数据的元数据或属性,比如设备ID,位置,类型等。标签可以用来过滤或分组数据。
- 字段(field):表示数据的值或内容,比如数值,字符串,布尔值等。字段可以用来计算或分析数据。
- 时间戳(timestamp):表示数据的时间点或区间,比如秒,毫秒,纳秒等。时间戳可以用来排序或窗口化数据。
行协议的格式如下:
measurement,tag_key=tag_value field_key=field_value timestamp |
例如,一个表示温度的行协议可以是这样的:
temperature,device_id=123,location=room1 value=25.6 1631377078000000000 |
这表示在1631377078000000000纳秒(2023-09-11T15:17:58Z)时,设备ID为123,位置为room1的温度值为25.6摄氏度。
设计原则
为了使数据模型易于查询且性能高效,需要遵循以下设计原则:
- 将常用的元数据或属性存储为标签,将变化的数值存储为字段。标签是被索引的,字段不是。这意味着通过标签过滤或分组数据比通过字段更快。例如,在查询某个位置的电表读数时,可以通过
location标签快速定位到相关的数据点,而不需要扫描所有的字段值。 - 将每个属性存储为单独的标签,而不是将多个属性拼接在一起。这样可以避免在查询时使用正则表达式来解析复杂的标签值。正则表达式会降低查询性能和可读性。例如,在查询某个区域的水表读数时,可以通过
region标签直接过滤出相关的数据点,而不需要从location标签中提取出区域信息。 - 避免在测量,标签和字段中存储数据。如果在这些要素中存储数据,会导致高基数(cardinality)问题。基数是指不同的测量和标签组合的数量。高基数会消耗更多的内存和CPU资源,并降低查询性能。例如,在存储电表读数时,应该将设备ID作为标签而不是测量或字段。
- 避免使用保留关键字或特殊字符作为标签和字段的名称。如果使用了Flux关键字作为名称,则需要在查询时用双引号括起来。如果使用了非字母数字字符作为名称,则需要在查询时用方括号表示法。
- 避免在同一个架构中使用相同的名称作为标签和字段。如果有一个标签和一个字段有相同的名称,则查询结果可能会出现不可预测的情况。
接收数据
收集数据是InfluxDB的第一个步骤,它指的是如何将时序型数据从不同的来源传输到InfluxDB中。时序型数据可以来自于各种设备,应用程序,服务,监控系统,日志系统等。为了方便地收集数据,InfluxDB提供了多种方法,包括:
- 使用Telegraf代理。Telegraf是一个开源的插件驱动的代理,它可以从各种输入源收集时序型数据,并且将其发送到各种输出目标。Telegraf支持超过200个插件,覆盖了常见的数据来源和目标。你可以使用Telegraf来轻松地将数据从你的设备或应用程序发送到InfluxDB中。
- 使用Flux语言。Flux是一种功能性的数据脚本语言,它可以用来查询,转换,分析和操作时序型数据。Flux也可以用来从其他数据库或服务中导入时序型数据到InfluxDB中。你可以使用Flux来编写自定义的数据收集逻辑,并且定期执行它。
- 使用HTTP API。HTTP API是InfluxDB提供的一种基于HTTP协议的接口,它可以用来执行各种操作,包括写入和查询数据。你可以使用HTTP API来直接向InfluxDB发送时序型数据,或者从其他服务中获取时序型数据并转发到InfluxDB中。
- 使用客户端库。客户端库是一些封装了InfluxDB的HTTP API的编程语言库,它们可以让你在你喜欢的编程语言中使用InfluxDB。客户端库支持多种语言,如Java, Python, Go, Ruby等。你可以使用客户端库来在你的代码中集成InfluxDB,并且向其发送时序型数据。
每种方法都有其优缺点,你可以根据你的需求和场景来选择合适的方法。下面我会简单地比较一下这些方法:
| 方法 | 优点 | 缺点 |
|---|---|---|
| Telegraf | 简单易用,支持多种插件,高效稳定 | 不够灵活,不能处理复杂的逻辑 |
| Flux | 强大灵活,支持多种函数和操作符,易于调试 | 需要学习新的语言,性能可能受限 |
| HTTP API | 直接高效,支持多种格式和参数,兼容多种工具 | 需要编写HTTP请求,不够友好 |
| 客户端库 | 方便集成,支持多种语言,提供高级功能 | 需要安装依赖,可能存在兼容性问题 |
写入数据
这里我提供一个基于Java的实现!
1.导入依赖
<dependency> |
2.创建连接
package example; |
3.写入数据
import com.influxdb.client.WriteApiBlocking; |
查询数据
在InfluxDB2.3版本中,用的是Flux语法,这个在以前1.x的版本中用的是InfluxQL语法.
查询InfluxDB的数据主要是以下步骤:
- 定义你的数据源。你需要使用from()函数来指定你要查询的存储桶的名称或ID。
- 定义你的时间范围。你需要使用range()函数来指定你要查询的时间范围,比如最近一小时,最近一天等。
- 定义你的数据过滤条件。你需要使用filter()函数来指定你要查询的数据的条件,比如度量名称,字段名称,标签名称或值等。
- 定义你的数据操作或分析方法。你可以使用各种Flux或InfluxQL函数来对数据进行操作或分析,比如求平均值,求标准差,求百分比,绘制图表等。
示例
这个查询会从example-bucket存储桶中获取最近一小时内度量为temperature的数据,并且对_value列求平均值。
from(bucket: "example-bucket") |
InfluxDB提供了很多函数,可以参考官方文档:使用 Flux 查询数据,或者文章结尾参考的网址!
在官方的控制面板,也可以看到各个API的说明!
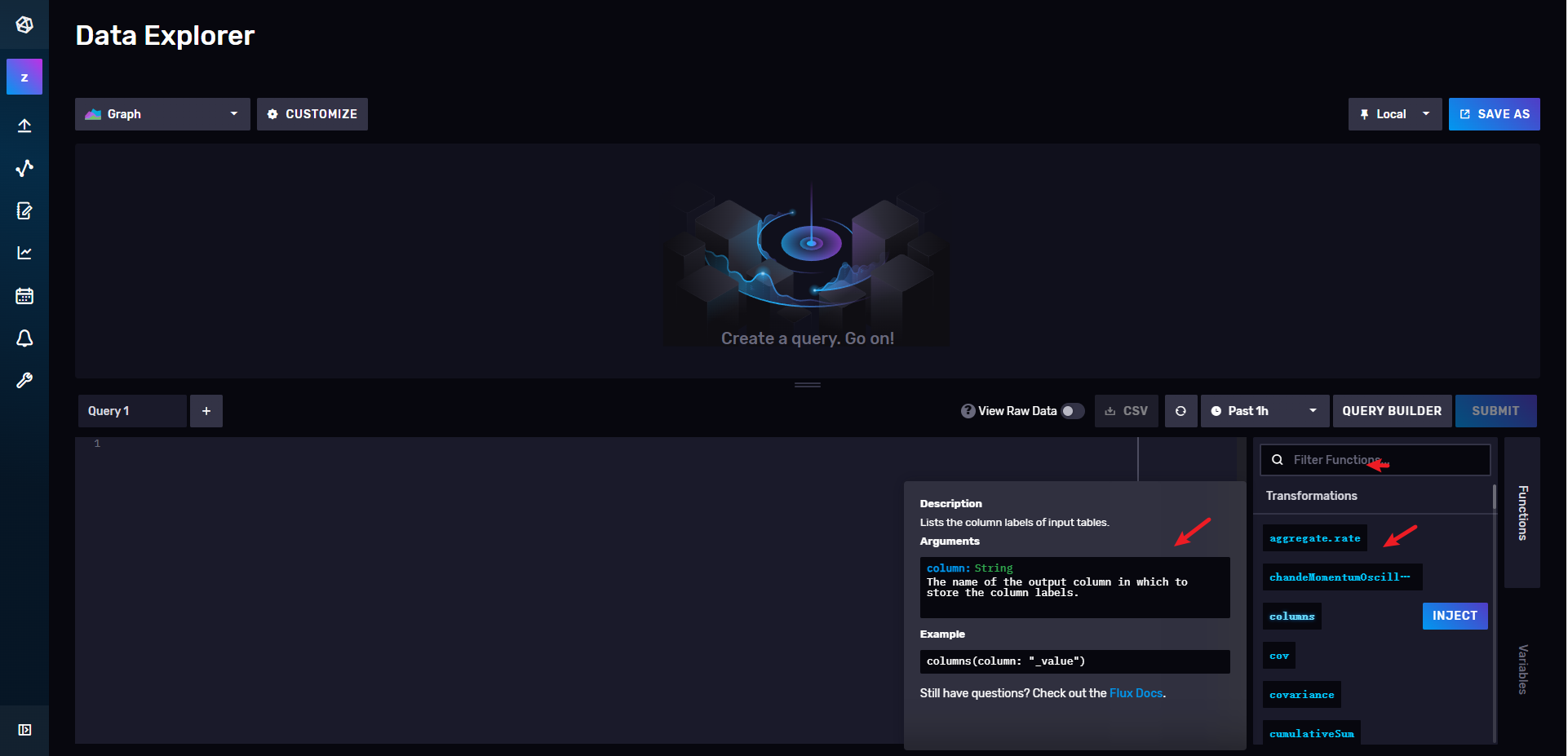
删除数据
| 参数 | 类型 | 说明 | 示例 |
|---|---|---|---|
| 请求方法 | 字符串 | 指定HTTP请求的方法,必须为POST | POST |
| 标题 | 字典 | 指定HTTP请求的头部信息,包括授权和内容类型 | {“Authorization”: “Token mytoken”, “Content-Type”: “application/json”} |
| 查询参数 | 字典 | 指定HTTP请求的查询参数,包括组织名称或ID和存储桶名称或ID | {“org”: “myorg”, “bucket”: “mybucket”} |
| 请求正文 | JSON对象 | 指定HTTP请求的正文内容,包括开始时间,结束时间和删除条件语句 | {“start”: “1970-01-01T00:00:00Z”, “stop”: “2023-09-11T15:17:58Z”, “predicate”: “_measurement=”temperature” AND value>30”} |
- 删除具有特定标签值的特定点
curl --request POST http://localhost:8086/api/v2/delete?org=example-org&bucket=example-bucket \ |
- 删除指定时间范围内的说有点
curl --request POST http://localhost:8086/api/v2/delete?org=example-org&bucket=example-bucket \ |
如果请求成功,你应该看到一个空白的响应。如果请求失败,你应该看到一个包含错误信息的响应。
定时任务
InfluxDB中的定时任务是一种使用Flux语言编写的定期执行的脚本,它可以对输入的数据流进行修改或分析,然后将修改后的数据写回到InfluxDB或执行其他操作。定时任务的功能包括:
- 数据降采样:数据降采样是一种减少数据量和存储空间的方法,它可以将高精度或高频率的数据转换为低精度或低频率的数据,比如将每秒的数据转换为每分钟或每小时的数据。数据降采样可以提高查询效率,降低存储成本,增加数据保留期限。你可以使用定时任务来定期对你的数据进行降采样,并且将降采样后的数据存储在一个新的存储桶中。
- 数据清洗:数据清洗是一种提高数据质量和可用性的方法,它可以将不完整,不准确,不一致或无关的数据进行修改或删除,比如将空值填充,将异常值替换,将重复值去除,或者将无用值删除。数据清洗可以提高分析准确性,减少错误率,增加信任度。你可以使用定时任务来定期对你的数据进行清洗,并且将清洗后的数据写回到原来的存储桶中。
- 数据分析:数据分析是一种从数据中提取有价值信息和知识的方法,它可以将原始数据进行转换,计算,统计,聚合或可视化,比如求平均值,求标准差,求百分比,绘制图表等。数据分析可以提高决策支持,发现规律,预测趋势。你可以使用定时任务来定期对你的数据进行分析,并且将分析结果存储在一个新的存储桶中或发送到其他服务中。
- 数据告警:数据告警是一种根据数据状态或变化触发通知或动作的方法,它可以将实时或历史数据与预设的阈值或条件进行比较,并且在满足条件时发送邮件,短信,电话等通知方式,或者执行其他操作,比如调整参数,启动备份等。数据告警可以提高监控效果,及时响应,防止危机。你可以使用定时任务来定期对你的数据进行告警,并且将告警信息发送到指定的目标中
示例
// Task options |
备份还原数据
备份
influx backup <backup-path> -t <root-token>
还原
所有数据
influx restore /backups/2020-01-20_12-00/
特定桶数据
influx restore \
/backups/2020-01-20_12-00/ \
--bucket example-bucket
# OR
influx restore \
/backups/2020-01-20_12-00/ \
--bucket-id 000000000000
使用实例
influxdata/influxdb-client-java
常见问题
可以参考:常见问题 |InfluxDB OSS 2.3 文档 (influxdata.com)
参考
 微信
微信- 支付宝



🎉 博客更新啦!
是不是觉得页面焕然一新?没错!为了更好的体验,我们更换了全新的主题。
旧主题年久失修 😥,而且过于花哨,所以选择了更简洁、更易用的新主题。希望大家喜欢!
我的个人站点已整合到顶部"我的站点"菜单中,欢迎访问体验!若存在无法访问的情况,可以及时反馈!✨

公众号