
人人都能看懂的HTTP学习笔记
HTTP的基本概念
整体架构
flowchart TD |
HTTP请求-响应流程图
sequenceDiagram |
生活案例
把HTTP通信想象成你去一家图书馆借书。
- 你(客户端) 想借一本书(资源)。
- 你知道书的准确位置(URL),比如“三楼社科区A-18架第3排”。
- 你填写一张借书单(HTTP请求)并交给图书管理员(服务器)。
- 图书管理员根据单子找到书,连同借阅凭证一起给你(HTTP响应)。
- 如果书不在或者你没借书证,他会告诉你“没找到”(404)或“请出示证件”(401)。
真实案例
在一个电商网站中,当你点击“我的订单”时:
- 你的浏览器(前端应用,如Vue/React)会发起一个HTTP GET 请求,URL可能是 https://api.ecommerce.com/orders?user_id=123。
- 这个请求通过互联网发送到电商的后端API服务器。
- 服务器验证你的身份,然后去数据库查询用户123的所有订单信息。
- 服务器将订单信息打包成一个JSON格式的字符串,放入HTTP响应体中,并返回给你的浏览器。
- 浏览器接收到JSON数据后,动态地将订单列表渲染到页面上。
在这个案例中,HTTP扮演了前后端数据通信的“信使”角色。
经典问题
问题: 当你在浏览器地址栏里输入一个URL,然后按下回车,直到你看到页面,这中间发生了什么?
1. 应用层 - URL解析与HTTP请求构建:
- 浏览器首先会解析我输入的URL,识别出协议(HTTP/HTTPS)、域名、端口、路径等信息。
- 它会构建一个HTTP请求报文,最核心的是请求行,比如 GET /index.html HTTP/1.1,以及包含Host在内的各种请求头。
2. 应用层 - DNS解析:
- 浏览器需要将URL中的域名(比如 www.example.com)解析成服务器的IP地址。
- 它会依次查询:浏览器缓存 -> 操作系统缓存 -> 本地Hosts文件 -> 本地DNS服务器。如果都找不到,本地DNS服务器会向根DNS服务器发起递归查询,最终找到目标IP地址。
3. 传输层 - TCP连接(三次握手):
- 知道了服务器IP和端口(HTTP默认80,HTTPS默认443)后,浏览器会通过TCP协议与服务器建立连接。
- 这个过程就是著名的“三次握手”:客户端发送SYN包,服务器回复SYN+ACK包,客户端再回复ACK包,连接建立。如果是HTTPS,这里还会进行TLS握手。
4. 网络层 - IP寻址与路由:
- TCP将HTTP请求报文分割成TCP报文段,并打包成IP数据包。通过IP寻址和路由器一跳一跳的转发,最终将数据包发送到目标服务器。
5. 服务器处理请求:
- 服务器接收到请求后,Web服务器(如Nginx)会进行处理,可能会将请求转发给后端的业务逻辑(如Node.js, Tomcat)。
- 后端应用处理请求,可能涉及数据库查询等操作,然后生成一个HTTP响应报文。
6. 返回响应与浏览器渲染:
- 服务器将HTTP响应报文(包含状态码200 OK和HTML页面内容)通过TCP连接发回给浏览器。
- 浏览器接收到响应后,开始解析HTML,构建DOM树。同时,如果HTML中包含CSS、JavaScript、图片等外部资源,浏览器会重复上述过程为每个资源发起新的HTTP请求。
- 最终,浏览器将DOM树、CSSOM树结合,进行布局(Layout)和绘制(Paint),将完整的页面呈现给我。
7. 连接关闭(四次挥手):
- 在HTTP/1.1的持久连接下,TCP连接可能不会立即关闭,以便复用。但最终会通过“四次挥手”来断开连接。
补充知识
CDN
- 流程中的位置:DNS解析阶段
- 核心概念: CDN(Content Delivery Network,内容分发网络)本质上是一个分布式的缓存系统。它将网站的静态资源(如图片、CSS、JavaScript文件,甚至部分动态内容)缓存到全球各地、靠近用户的“边缘节点”(Edge Node)上。
- 解决的问题: 物理延迟。如果你的服务器在纽约,上海的用户访问它,数据来回需要跨越太平洋,光速的限制是无法逾越的。CDN通过让用户访问离他最近的节点来获取资源,极大地缩短了物理距离,从而降低延迟。
sequenceDiagram |
负载均衡
- 流程中的位置:TCP连接建立阶段
- 核心概念: 负载均衡器是服务器集群的“交通警察”。当大量请求涌入时,它会将这些请求根据预设的策略(如轮询、最少连接数、IP哈希)分发到后方的多台Web服务器上。
- 解决的问题: 单点瓶颈和可扩展性。单个服务器的处理能力是有限的,无法应对高并发场景。负载均衡能将压力均分,使得系统可以通过简单地增加服务器数量(水平扩展)来提升整体处理能力。
flowchart TD |
HTTP/2多路复用
- 流程中的位置:浏览器获取页面资源阶段
- 核心概念: HTTP/1.1存在“队头阻塞”(Head-of-Line Blocking)问题。虽然浏览器可以开多个TCP连接(通常6-8个),但每个连接同一时间只能处理一个请求-响应。而HTTP/2的多路复用(Multiplexing)允许在单个TCP连接上同时发送和接收多个请求和响应,它们被分解成更小的帧,可以并行、交错地传输。
- 解决的问题: 网络传输效率。它消除了队头阻塞,减少了TCP连接建立的开销,使得页面资源加载速度更快。
flowchart TD |
HTTP协议
“无状态”是HTTP协议最根本的设计哲学之一。理解它,是理解为何需要Cookie、Session、Token等会话管理技术的起点。这是架构设计和面试中的高频话题。
在现代的分布式、微服务架构和云原生环境下,服务的“无状态性”变得前所未有的重要。因为一个无状态的服务可以被轻易地水平扩展(简单地增加服务器实例),也可以被负载均衡器自由地调度到任何一台机器上,而无需担心会话数据丢失。将“无状态”与“可伸缩性(Scalability)”强关联,是现代架构师的必备思维。
- Cookie-Session 时代: Cookie只在客户端存储一个无意义的session_id,所有用户的具体状态数据(如购物车、登录信息)都保存在服务器端的内存或数据库中。
- Token-Based (JWT) 时代: 为了让后端服务也“无状态”,我们不再在服务器端存储会话数据。取而代之的是,服务器在用户认证成功后,生成一个加密的、包含用户信息的Token (如JWT),并将其发送给客户端。客户端在后续请求中携带这个Token,服务器只需验证Token的合法性即可,无需查询自己的“会话存储”。这使得后端服务可以无限水平扩展。
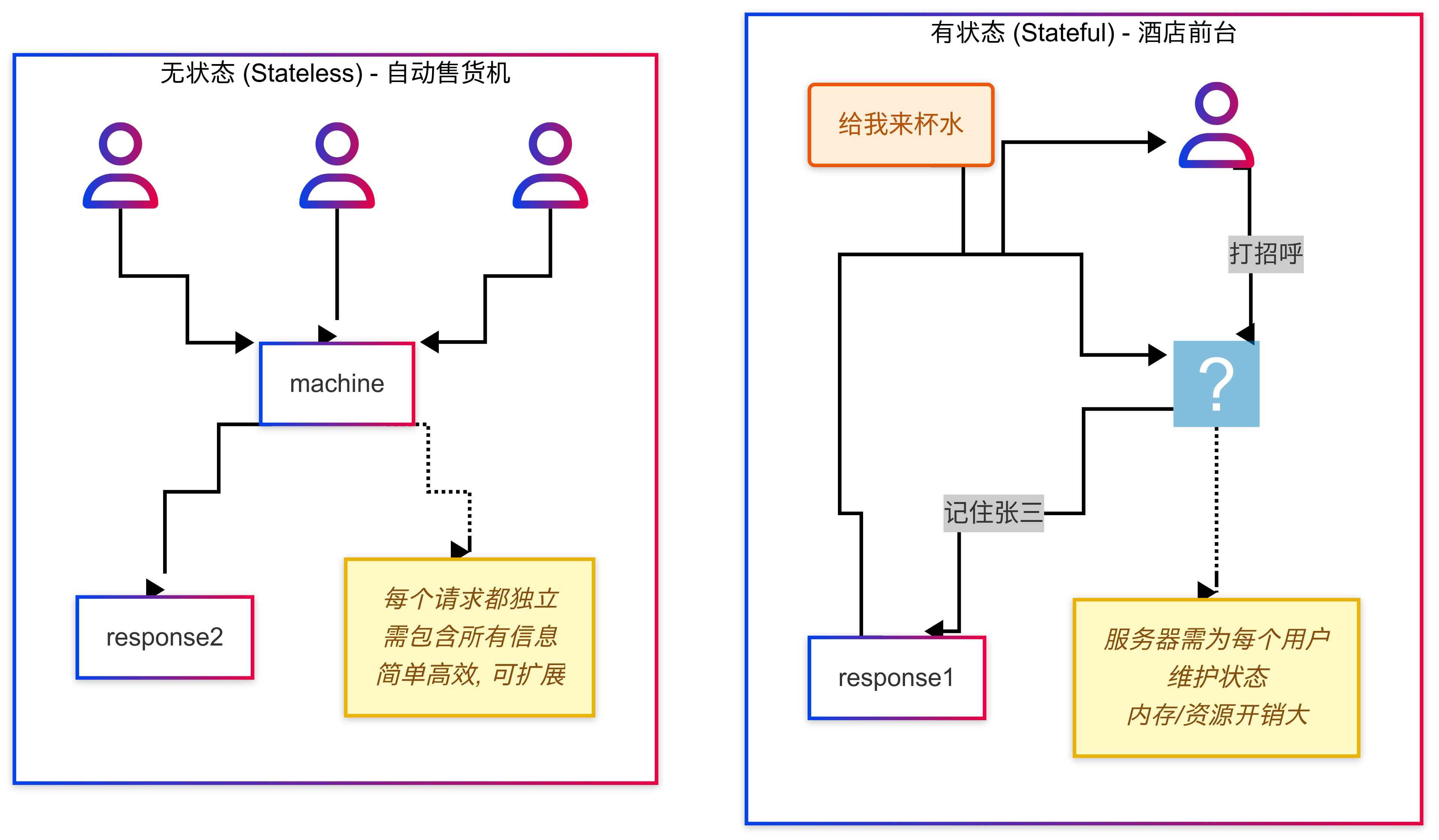
生活案例
- 无状态协议就像是与一个记忆力很差的自动售货机打交道。你每次投币买东西,它都会给你对应的商品,但它完全不记得你之前买过什么。如果你想连续买两瓶可乐,你必须完整地做两次“投币-按按钮”的操作。
- 有状态协议则像是你和一个熟悉的酒吧老板打交道。你第一次去说:“我是张三,以后我的酒都记在账上。” 老板记住了。之后你每次去,只需要说:“老样子,来一杯。” 他就知道该给你什么,并记在你的账上。
真实案例
考虑一个大型电商的“购物车”功能。
- 早期设计(有状态): 每个用户的购物车内容都存在Web服务器的内存(Session)里。当用户量巨大时,服务器内存会成为瓶颈。如果该服务器宕机,用户的购物车数据就全部丢失了。而且,负载均衡器必须使用“粘性会话”(Sticky Session),把同一个用户的请求始终转发到同一台服务器,这降低了负载均衡的灵活性。
- 现代设计(无状态): 用户在未登录时,购物车信息被加密存储在客户端的Cookie或LocalStorage里。用户登录后,购物车信息被同步到服务端的分布式缓存(如Redis)或数据库中。Web服务器本身不存储任何购物车状态,每次请求过来,它都根据请求中的用户信息(可能是session_id或JWT)去后端存储中查询购物车数据。这样的服务器可以无限水平扩展。
经典问题
面试题: 既然HTTP是无状态的,那我们是如何实现用户登录状态的保持的?请比较一下基于Session和基于JWT的两种主要方案。
是的,HTTP的无状态性意味着服务器本身不记录客户端的状态,这就需要我们引入额外的机制来管理会话,其中最主流的就是基于Session和基于Token(特别是JWT)的方案。
1. 基于Cookie-Session的方案(传统方案):
* 流程: 客户端首次登录成功后,服务器会创建一个Session对象,里面存储着用户的状态信息(如用户ID、角色等),并为这个Session生成一个唯一的session_id。然后,服务器通过Set-Cookie响应头将这个session_id返回给客户端。客户端浏览器会自动保存这个Cookie。在后续的每次请求中,浏览器都会自动带上这个session_id。服务器收到请求后,通过session_id找到对应的Session,从而识别出用户身份。
* 优点: 状态数据存储在服务端,相对安全;客户端Cookie中只存储无意义的ID,数据量小。
* 缺点: 服务器有状态,不易扩展。在分布式环境下,需要解决Session共享问题,比如使用粘性会话、Session复制或集中的Session存储(如Redis),这增加了架构复杂性。
2. 基于JWT(JSON Web Token)的方案(现代主流):
* 流程: 客户端登录成功后,服务器不再创建Session。而是将用户的核心信息(如用户ID、角色、过期时间)编码成一个JWT字符串。这个JWT本身包含了签名,可以防止被篡改。服务器将这个JWT直接返回给客户端。客户端通常将其存储在LocalStorage或HttpOnly Cookie中。在后续请求中,客户端通过HTTP的Authorization头(通常是Bearer
* 优点: 服务器完全无状态。服务器无需存储任何会话信息,只需验证JWT签名的有效性即可。这使得后端服务可以非常容易地进行水平扩展。天然地避免了CSRF攻击(如果存储在LocalStorage中)。
* 缺点: Token本身可能较大;一旦签发,在过期前难以强制吊销;由于信息存在客户端,不适合存放敏感数据。
总结对比: Session方案将状态的包袱留给了服务端,而JWT方案则将状态(以加密Token的形式)“甩”给了客户端。在当今追求高可伸缩性、跨域通信和微服务的架构下,JWT这种服务端无状态的方案已成为事实上的主流选择。
补充知识
请求与线程的关系
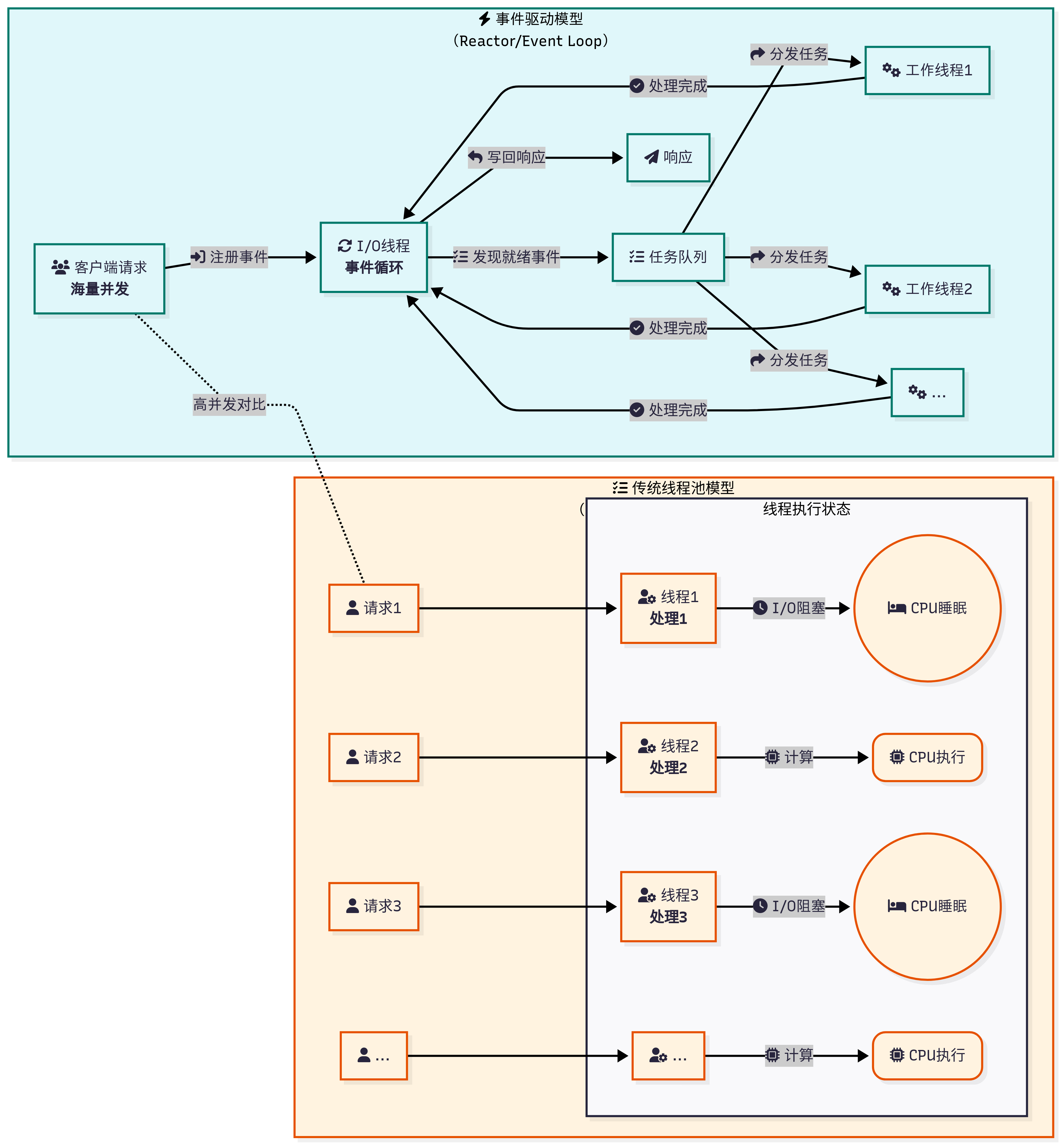
一个HTTP请求通常会由一个后台线程来处理,但这只是最终呈现的结果。前端请求与后台线程的真正关系,取决于Web服务器的I/O模型和并发模型。
这个关系取决于服务器的并发模型。
- 在传统的阻塞I/O模型下,可以近似地认为一个请求独占一个线程。这种模式简单直观,但由于线程开销巨大,无法支持高并发。
- 在现代高性能服务器普遍采用的非阻塞I/O(或异步I/O)模型下,这种关系被解耦了。前端的大量请求首先由少数几个I/O线程来接收和分发,这些I/O线程利用事件循环机制,可以高效地管理成千上万的并发连接。而请求中真正的业务逻辑处理,则被封装成任务,交由一个数量固定的后台工作线程池来执行。
因此,前端的请求和后台的多线程是多对多的关系,但中间通过一个高效的I/O事件分发层进行了调度。我们Java后台开发中讨论的‘线程共享’,通常指的是工作线程池中的线程共享数据库连接池、缓存等公共资源。而我们说‘这个请求很耗时’,通常是指它在工作线程中执行业务逻辑(比如一个复杂的数据库查询)花费了很长时间,但这并不会阻塞I/O线程接收其他新的请求。
Cookie
Cookie是一种允许服务器在客户端(浏览器)上存储少量文本信息的机制。其核心流程是:
- 服务器通过在HTTP响应报文中添加Set-Cookie头部,将信息“种”到客户端。
- 客户端收到后,会将这些信息存储起来。
- 当客户端再次向同一个服务器发起请求时,会自动在HTTP请求报文中添加Cookie头部,将之前存储的信息回传给服务器。
HttpOnly属性:
- 作用: 这是最重要的安全属性。设置了HttpOnly的Cookie,将无法通过JavaScript的document.cookie API进行读写。
- 解决的问题: 有效地防御了绝大部分的跨站脚本攻击(XSS)。黑客即使在你的页面注入了恶意脚本,也无法窃取到这个Cookie,从而无法轻易地劫持你的会话。
- 业界标准: 所有承载敏感信息(如session_id, token)的Cookie,必须设置为HttpOnly。
Secure属性:
- 作用: 设置了Secure的Cookie,只有在HTTPS连接中才会被发送。在HTTP连接中,浏览器会忽略这个Cookie,不会发送它。
- 解决的问题: 防止Cookie在不安全的HTTP连接中被中间人嗅探和窃取。
- 业界标准: 所有承载敏感信息的Cookie,必须设置为Secure。
SameSite属性:
- 作用: 这是防御**跨站请求伪造(CSRF)**攻击的利器。它定义了浏览器在**跨站请求**时是否应发送Cookie。
- 它有三个值:
- Strict: 最严格。任何跨站请求(比如从A网站点击链接到B网站),都不会携带B网站的Cookie。
- Lax: (目前多数浏览器的默认值) 在一些安全的顶层导航(如点击链接、GET表单)时允许发送Cookie,但在POST请求、img、iframe等加载中则会禁止。
- None: 任何跨站请求都会发送Cookie。但必须同时设置Secure属性,否则无效。常用于需要跨域认证的API场景。
- 解决的问题: CSRF攻击的核心是利用了用户在A网站的操作,会自动携带B网站的Cookie去请求B网站。SameSite属性正是打破了这个“自动携带”的链条。
%%{init: { "themeVariables": { "sequenceNumberColor": "#546E7A", "actorBorder": "#78909C", "actorBkg": "#E3F2FD", "actorTextColor": "#1E88E5", "noteBkgColor": "#fffde7", "noteBorderColor": "#FFD600" }, "theme": "neo" } }%% |
生活案例
Cookie就像是游乐场的腕带。
- 你买票入场时(登录),工作人员(服务器)给你戴上一个腕带(Set-Cookie),上面有个独一无二的条形码(session_id)。
- HttpOnly属性就像这个腕带是一次性锁死的,你自己用手摘不下来(JS无法读取),只能由专门的机器(浏览器协议)来识别。
- Secure属性意味着只有在游乐场官方通道(HTTPS)才能扫描这个腕带,你在外面的小卖部(HTTP)用不了。
- SameSite=Strict属性就像是规定,这个腕带只能在游乐场内部使用。如果你跑到隔壁的商场,想用这个腕带打折,商场的扫描仪(其他网站)会拒绝识别。
真实案例
场景: 设计一个银行网站的“记住我”功能。
- 错误实践: 将用户的明文用户名和密码保存在普通Cookie中。这是极度危险的,一旦被XSS攻击,用户的凭证将立刻泄露。
- 正确实践:
- 用户登录时,如果勾选了“记住我”,服务器会生成一个长期的、高熵的、随机的令牌(Token)。
- 服务器在数据库中存储这个令牌,并关联到该用户,同时设置一个较长的过期时间(比如30天)。
- 服务器通过Set-Cookie将这个令牌返回给客户端,并必须设置以下属性:token=abc…xyz; Expires=…; HttpOnly; Secure; SameSite=Lax。
- 用户下次访问时,浏览器会自动携带这个令牌Cookie。服务器端的“自动登录”过滤器会检查这个令牌,在数据库中验证其有效性。如果有效,则为用户自动创建一次性的登录会话,实现“记住我”功能。
经典问题
HttpOnly和SameSite这两个Cookie属性分别是为了解决什么安全问题的?请具体说明。
这两个属性是现代Web安全中用于加固Cookie、防御两大核心攻击的关键手段。
- HttpOnly 主要防御的是跨站脚本攻击(XSS)。 XSS攻击的核心是攻击者在网页中注入了恶意的JavaScript脚本。在没有HttpOnly的情况下,这个脚本可以通过document.cookie窃取到用户的会话Cookie(比如session_id),然后发送到攻击者的服务器,攻击者就可以利用这个Cookie伪装成用户进行操作,这就是“会话劫持”。而设置了HttpOnly属性后,JavaScript就无法再访问这个Cookie,从根本上切断了XSS攻击窃取会话Cookie的路径,极大地提升了安全性。
- SameSite 主要防御的是跨站请求伪造(CSRF)。 CSRF攻击的核心是利用了浏览器在发送跨站请求时会自动携带目标站点Cookie的特性。攻击者会诱导已登录的用户(比如银行网站的用户)去点击一个恶意链接,这个链接会向银行服务器发起一个转账请求。由于浏览器会自动带上银行的Cookie,银行服务器会误以为这是用户的真实操作,从而导致资金被盗。SameSite属性通过限制跨站请求发送Cookie来防御这种攻击。SameSite=Strict最为严格,几乎禁止所有跨站Cookie发送;而Lax模式则是一种平衡,它允许在用户主动导航(如点击链接)这种风险较低的场景下发送Cookie,但在高风险的场景(如POST请求或通过
、'; } }, 1000); } // 辅助函数:创建占位内容 function createPlaceholder(text) { const placeholder = document.createElement('div'); placeholder.style.borderRadius = '8px'; placeholder.style.height = '246px'; placeholder.style.backgroundColor = '#f8f9fa'; placeholder.style.padding = '15px'; placeholder.style.display = 'flex'; placeholder.style.flexDirection = 'column'; placeholder.style.justifyContent = 'center'; placeholder.style.textAlign = 'center'; placeholder.textContent = text; return placeholder; } })();